阅读随记:What is the Difference Between COUNT(*), COUNT(1), COUNT(column name), and COUNT(DISTINCT column name)?
关于SQL的count()系列,找到了一篇非常好的文章:What is the Difference Between COUNT(*), COUNT(1), COUNT(column name), and COUNT(DISTINCT column name)?,这里简单记录一下。
强烈推荐阅读原文。
主要讨论以下count系列函数:
COUNT(*)COUNT(1)COUNT(column name)COUNT(DISTINCT column name)
COUNT(*) vs COUNT(1)
关于count(*)和count(1)的争论,网上各种各样的说法,可能参阅的文章越多,反而会使你更加疑惑。
答案简单来说,就是count(*)和count(1)没有任何区别。
So, is there any difference? The simple answer is no – there is no difference at all.
count(*)计算表中的总行数,包括NULL的行。count(1)和count(*)的语义略有不同,但是返回的结果是完全一样的。
在这里提前说一下语义略微的不同:count(*)使用*来填充每一行,而count(1)使用1来填充每一行。所以我们说count(*)和count(1)几乎没有任何区别。
(对count(1)来说1不过是一个非空表达式罢了。)
“1” is a non-null expression: so it’s the same as
COUNT(*). The optimizer recognizes it for what it is: trivial.
接下来我们创建一个表来测试。
Let’s test this claim using an example query. Suppose I have a table named
ordersthat contains these columns:
order_id: The ID of the order.customer_id: The ID of the customer who placed the order.order_value: The total value of the ordered items, in euros.payment_date: When the order was paid by the customer.
如果要知道表的行数,使用count(*):
1 | SELECT COUNT(*) AS number_of_rows FROM orders; |
或count(1):
1 | SELECT COUNT(1) AS number_of_rows FROM orders; |
在网上有一种广为流传的错误说法:count(1)统计表的第一列的行数,而count(*)统计表的所有列的行数count(1)比count(*)快,因为count(1)只统计第1列的行数而count(*)统计所有列的行数
There’s a popular misconception that “1” in
COUNT(1)means “count the values in the first column and return the number of rows.” From that misconception follows a second: thatCOUNT(1)is faster because it will count only the first column, whileCOUNT(*)will use the whole table to get to the same result.
这种说法是不正确的!count()括号里面的数并没有什么实际意义,更不会代表所统计表的第几列。
比如:
1 | SELECT COUNT(-13) AS number_of_rows FROM orders; |
结果跟count(*)和count(1)是完全一样的。
或者再任性一点:
1 | SELECT COUNT("fxxk you") AS number_of_rows FROM orders; |
结果也是和上面一样的。
那么count()的括号内的内容到底是什么意思呢?其实只是一种非空表达式,用来填充用的罢了。
So what does the value in the parenthesis of
COUNT()mean? It’s the value that theCOUNT()function will assign to every row in the table. The function will then count how many times the asterisk (*) or (1) or (-13) has been assigned. Of course, it will be assigned a number of times that’s equal to the number of rows in the table. In other words,COUNT(1)assigns the value from the parentheses (number 1, in this case) to every row in the table, then the same function counts how many times the value in the parenthesis (1, in our case) has been assigned; naturally, this will always be equal to the number of rows in the table. The parentheses can contain any value; the only thing that won’t work will be leaving the parentheses empty.
因为count()括号中的值是什么并不重要,所以我们说count(*)和count(1)没有任何区别。更不会存在性能的差别,count(1)比count(*)快完全是无稽之谈。
Since it doesn’t matter which value you put in the parentheses, it follows that
COUNT(*)andCOUNT(1)are precisely the same. They are precisely the same because the value in theCOUNT()parentheses serves only to tell the query what it will count.If these statements are precisely the same, then there’s no difference in the performance. Don’t let the asterisk (*) make you think it has the same use as in
SELECT *statement. No,COUNT(*)will not go through the whole table before returning the number of rows, making itself slower thanCOUNT(1).
虽然在性能的battle上是平局,不过我们还是推荐使用count(*),因为这样看起来对SQL Boy比较友好😊,一眼能看懂是什么意思(计算表中的总行数,包括NULL)。
COUNT(*) vs COUNT(column name)
Always remember:
COUNT(column name)will only count rows where the given column is NOT NULL.
上面已经提到过了,count(*)和count(1)没有任何区别,那么count(*) 和count(column name)呢?这两个当然是有区别的:
count(*):统计表中所有行数,包括NULLcount(column name):只统计指定列名的行数,且不包括NULL
举个例子,表数据如下:
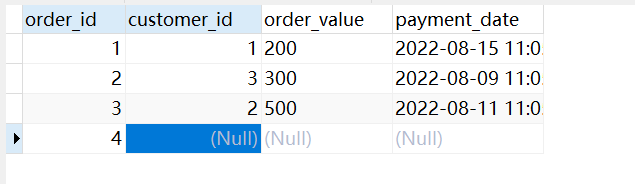
-
执行
SELECT COUNT(*) AS number_of_rows FROM orders;结果如下:
-
执行
SELECT COUNT(customer_id) AS number_of_rows FROM orders;结果如下:
我们还可以结合CASE来使用count():
1 | SELECT COUNT(CASE WHEN order_value > 250 THEN * END) AS significant_orders FROM orders; |
结果如下:
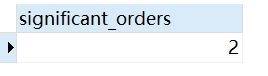
因为只统计了order_value列中value大于250的行数,所以统计结果为2。
上面的代码是使用
1来填充,当然也可以使用*来填充:SELECT COUNT(CASE WHEN order_value > 250 THEN '*' END) AS significant_orders FROM orders;
COUNT(column name) vs COUNT (DISTINCT column_name)
COUNT(column_name)will include duplicate values when counting. In contrast,COUNT (DISTINCT column_name)will count only distinct (unique) rows in the defined column.
至于COUNT(column_name) 和COUNT (DISTINCT column_name)的区别就更明显了:
COUNT(column_name):统计指定列中不包括NULL的行数(但包括重复值)COUNT (DISTINCT column_name):统计指定列中不包括NULL且不包括重复值的行数
比较一下SELECT COUNT(customer_id) AS number_of_rows FROM orders;和
SELECT COUNT(DISTINCT customer_id) AS number_of_rows FROM orders;的运行结果就清楚了。


