MySQL(三)
多表查询
查询语法:
1 | select |
例子:
1 | select * from emp,dep2; |
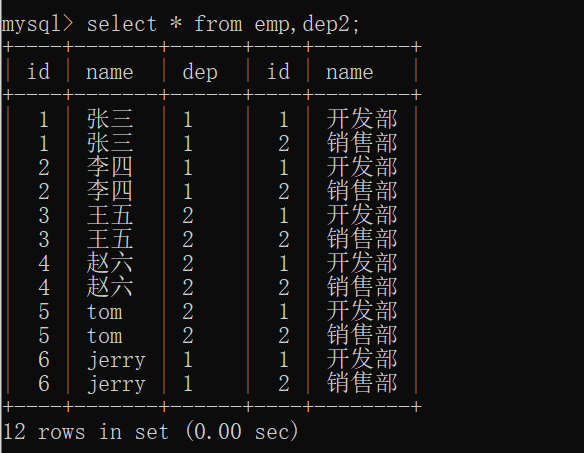
多表查询的运算类似于笛卡尔积。
笛卡尔积:有两个集合A,B,取这两个集合的所有组成情况。(这样就很有可能产生多条无用数据,比如说图中张三对应两个部门,显然第二条是无用的数据,因为dep(emp表的字段)对应着id(dep2的字段))
要完成多表查询,需要消除无用的数据
多表查询的分类:
- 内连接查询
- 外连接查询
- 子查询
内连接查询
内连接:
- 隐式内连接
- 显式内连接
隐式内连接
隐式内连接:使用where条件消除无用数据
例子:查询所有员工对应的部门信息
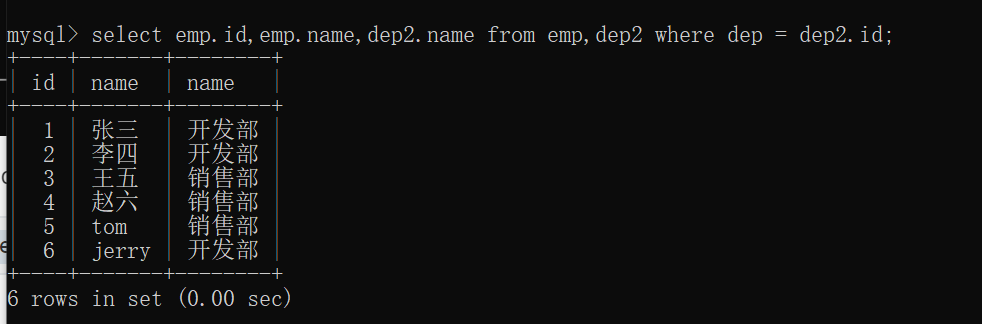
1 | select * from emp,dep2 where dep = dep2.id; |

其中dep字段和id(dep2中的字段)这两个字段是多余的,可以改进一下:
1 | select emp.id,emp.name,dep2.name from emp,dep2 where dep = dep2.id; |
显式内连接
语法:
1 | select 字段列表 from 表名1[inner] join 表名2 on 条件 |
例子:
1 | select * from emp [inner] join dep2 on emp.dep = dep2.id; |

内连接查询要明确以下几点:
- 从哪些表中查询数据
- 条件是什么
- 查询哪些字段
外连接查询
外连接:
- 左外连接
- 右外连接
左外连接
语法:
1 | select 字段列表 from 表1 left [outer] join 表2 on 条件; |
左(外)连接,左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
现在我们的emp表中有两个成员没有写部门:
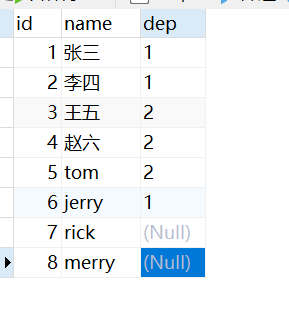
如果我们执行sql:
1 | select emp.*,dep2.name from emp,dep2 where dep = dep2.id; |
结果为:

很显然没有rick和merry的信息,因为他们的dep为null,不可能等于dep2.id。
现在如果要求:查询所有员工信息,如果员工有部门,则查询部门名称;没有部门,则不显示部门名称。
所以现在我们使用左外连接来查询:
1 | select emp.id,emp.name,dep2.name from emp left [outer] join dep2 on emp.dep = dep2.id; |
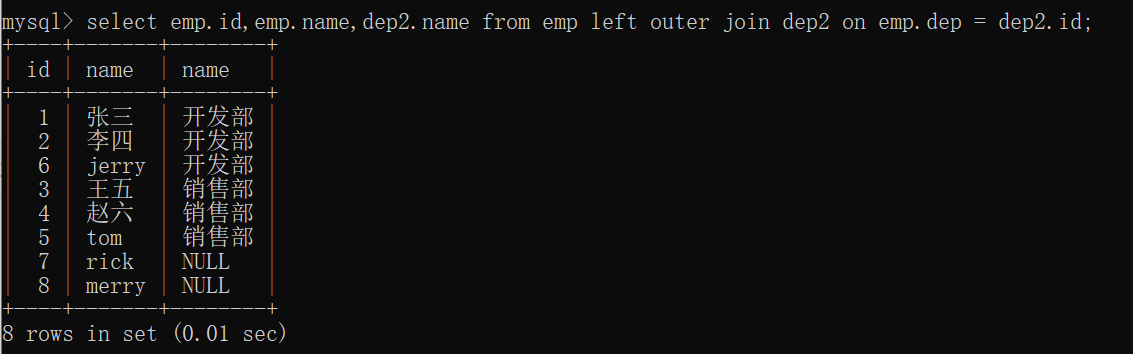
可以看到通过左外连接可以将没有部门的员工信息也显示出来。
从这个结果中可以更好地理解左连接:左表的记录将会全部表示出来,即图中

所有记录都会表示出来,而右表只会显示符合条件的记录:

即上图结果中第三个name(右表中的字段)只会显示符合条件的记录,右表记录缺失则显示为null

右外连接
在理解左连接后,有连接就很好理解了。
语法:
1 | select 字段列表 from 表1 right [outer] join 表2 on 条件; |
与左(外)连接相反,右(外)连接,左表只会显示符合搜索条件的记录,而右表的记录将会全部表示出来。左表记录不足的地方均为NULL。
例子:
1 | select emp.*,dep2.name from emp right [outer] join dep2 on emp.dep = dep2.id; |

子查询
子查询的定义:
子查询是将一个查询语句嵌套在另一个查询语句中;
在特定情况下,一个查询语句的条件需要另一个查询语句来获取,内层查询(inner query)语句的查询结果,可以为外层查询(outer query)语句提供查询条件。
子查询:查询中嵌套查询,称嵌套查询为子查询。
子查询特点(规范):
- 子查询必须放在小括号中
- 子查询一般放在比较操作符的右边,以增强代码可读性
- 子查询(小括号里的内容)可出现在几乎所有的SELECT子句中(如:SELECT子句、FROM子句、WHERE子句、ORDER BY子句、HAVING子句……)
例子,现有student表数据如下:

要查询表中年龄最大的学生的全部信息,如果只是输入以下sql语句,只能查询age这一个字段,而不是全部信息
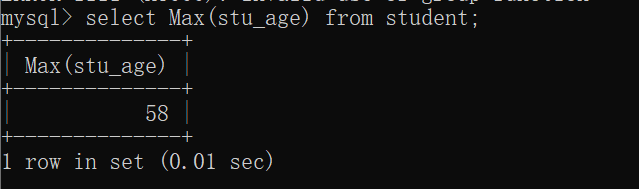
1 | select Max(stu_age) from student; |
而~~select * from student where stu_age=Max(stu_age);~~这样的sql语句是会报错的:

要查询到年龄最大的学生的所有信息,就需要使用子查询了,输入sql如下:
1 | select * from student where stu_age = (select Max(stu_age) from student); |

子查询分类
- 标量子查询(scalar subquery):返回1行1列一个值(单行单列)
- 行子查询(row subquery):返回的结果集是 1 行 N 列(单行多列)
- 列子查询(column subquery):返回的结果集是 N 行 1列(多行单列)
- 表子查询(table subquery):返回的结果集是 N 行 N 列(多行多列)
标量子查询
因为标量子查询返回1行1列是一个值,所以可以用来进行算术运算
可以使用=,>,<,>=,<=,<>(!=)操作符对子查询的结果进行比较
例子:查询student表中年龄小于平均年龄的学生的全部信息,输入sql:
1 | select * from student where stu_age < (select avg(stu_age) from student); |

行子查询
行子查询返回的结果集是1行多列
可以使用行表达式进行比较,可以使用=,>,<,>=,<=,<>(!=) in操作符
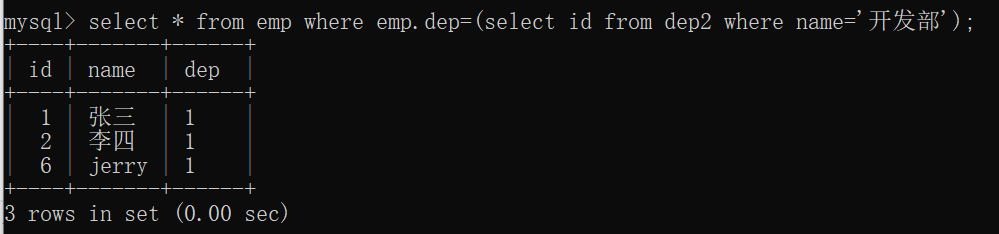
例子:现有emp表和dep2表数据如下:
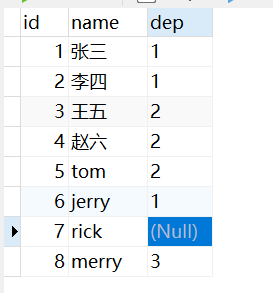
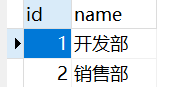
例子:我们要查询所有开发部员工的所有信息,输入sql如下:
1 | select * from emp where emp.dep=(select id from dep2 where name='开发部'); |
列子查询
列子查询返回的结果集是多行1列
必须使用in,any,all操作符对子查询返回的结果进行比较
注意:any和all操作符不能单独使用,其前面必须加上单行比较操作符=,>,<,>=,<=,<>(!=)
MySQL使用IN、EXISTS、ANY、ALL关键字的子查询
- 带
any关键字的子查询:any关键字表示满足其中任意一个条件。使用any关键字时,只要满足内层查询语句返回的结果中的任意一个,就可以通过该条件来执行外层查询语句。
例子:现有test表如下:
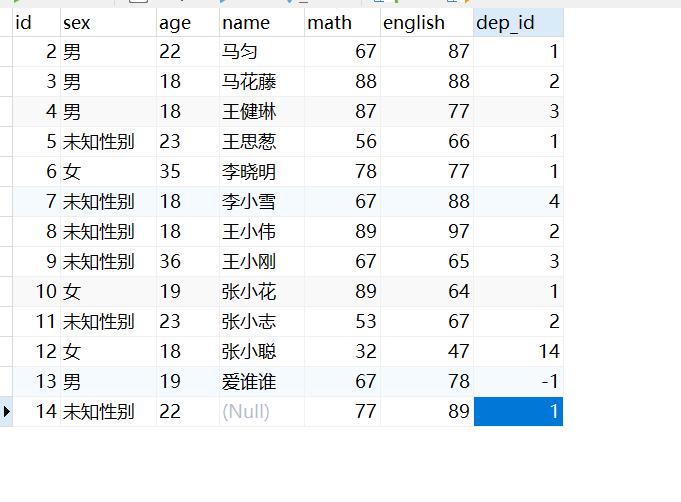
dep2表的数据同上,先要查询test表中所有部门编号合法的员工的所有数据(即test表中dep_id字段为1或2)。输入sql:
1 | select * from test where test.dep_id = any (select dep2.id from dep2); |

- 带
all关键字的子查询:all关键字表示满足所有条件。使用all关键字时**,只有满足内层查询语句返回的所有结果,才可以执行外层查询语句**。
例子:还是对test表,查询所有dep_id字段大于dep2表中id的员工的所有信息(即test表中的dep_id大于1且大于2)。输入sql:
1 | select * from test where test.dep_id > all (select dep2.id from dep2); |

表子查询
表字查询:返回结果为多行多列
表子查询的结果可以作为一张虚拟表参与查询
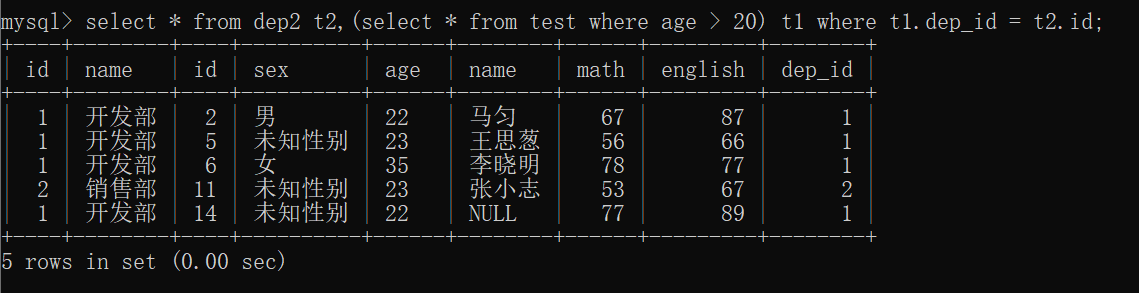
例子:还是对上述test表和dep2表,我们要查询员工年龄大于20的员工信息和部门信息。输入sql:
1 | -- 使用表子查询 |

多表查询练习
题目相关表的sql语句如下:
1 | -- 部门表 |
创建成功后相应表以及数据为:

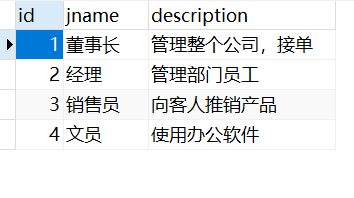
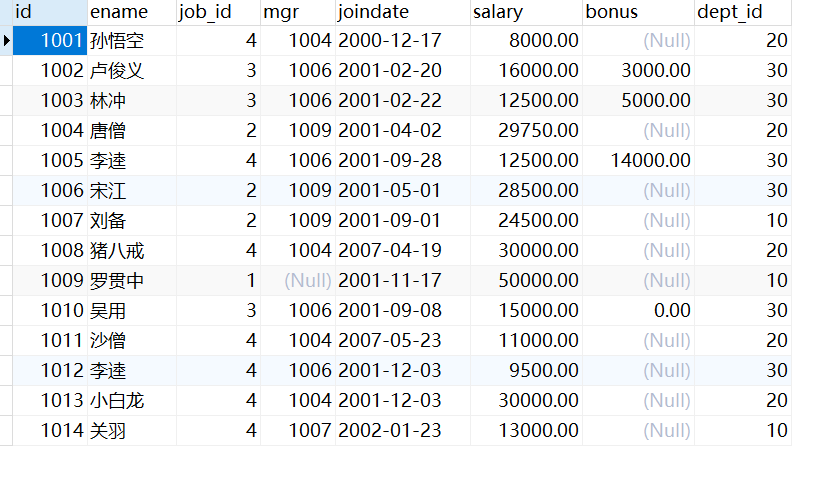
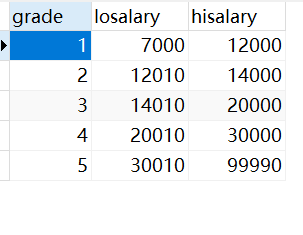
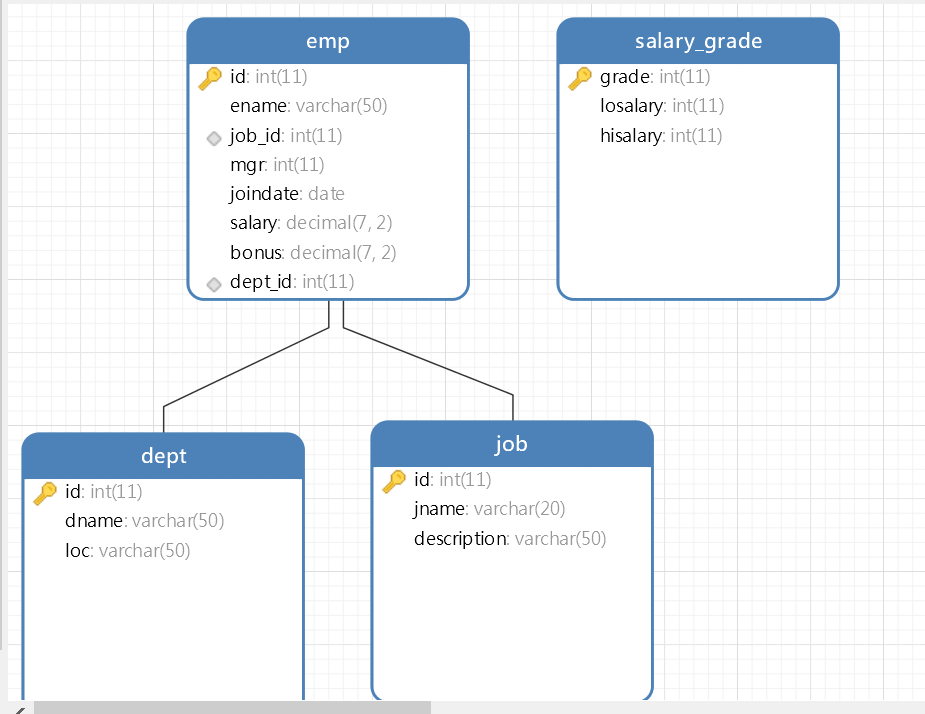
需求:
练习1
1.查询所有员工信息。(包括员工编号,员工姓名,工资,职务名称,职务描述)
1 | -- 隐式内连接 |

练习2
2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
1 | -- 隐式内连接 |
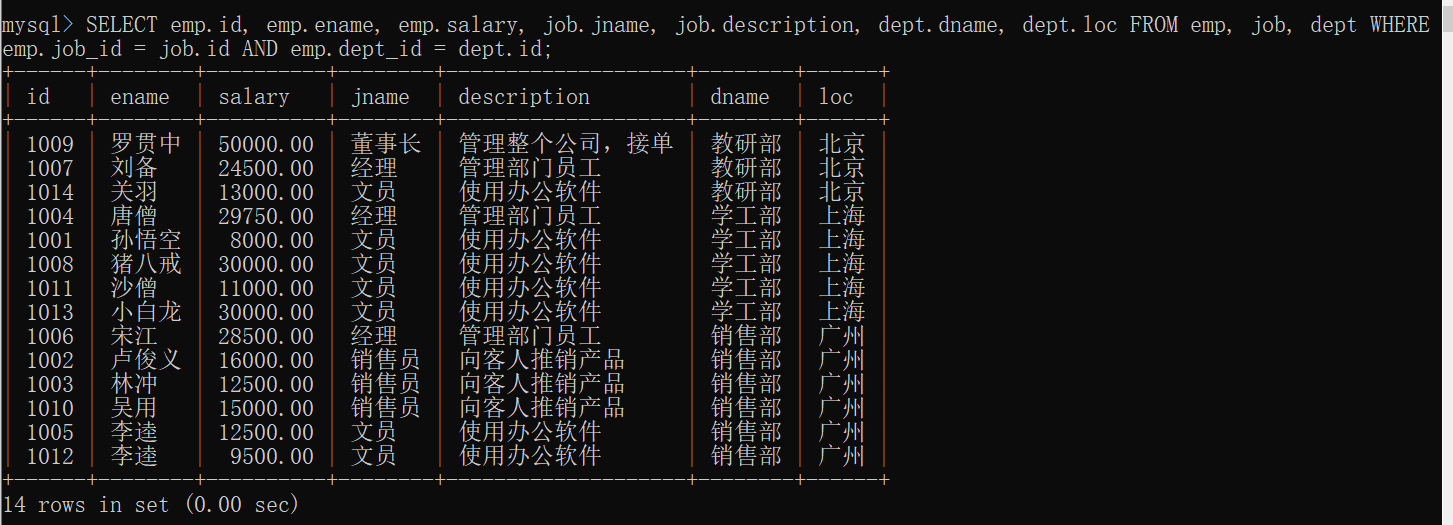
练习3
3.查询员工姓名,工资,工资等级
1 | -- 隐式内连接 |

练习4
4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
1 | -- 隐式内连接 |

练习5
5.查询部门编号,部门名称,部门位置,部门人数
1 | -- 使用分组查询,按照emp.dept_id完成分组,查询count(id)求出部门人数 |

练习6
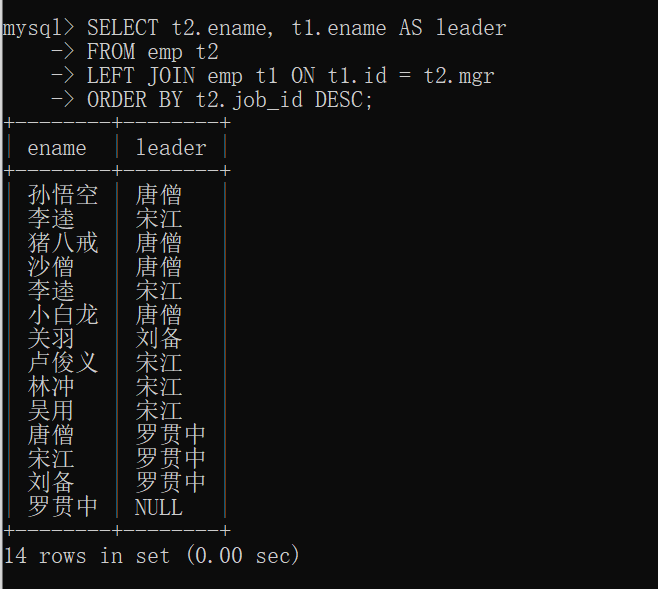
6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
(emp表中的mgr字段对应着员工的直接上级的id,即emp表的id和mgr是自关联)
因为没有领导的员工也需要查询所以可以使用左连接
1 | -- 即使是自关联同样需要两个表,使用关键字as(可省略)取别名来实现一表两用 |