MySQL(二)
约束
相关文章链接
约束:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
分类:
primary key 主键约束not null 非空约束unique 唯一约束foreign key 外键约束
(这四种约束以后都可以直接在navicat上操作,不需要输入命令行)
非空约束
not null, 非空约束,即该字段的值不能为null
1
2
3
4
5
6
7
8
9
|
create table stu(
id int,
name varchar(20) not null
);
alter table stu modify name varchar(20) not null;
alter table stu modify name varchar(20);
|
唯一约束
unique ,唯一约束,即该字段的值在表中不能有重复
注意:mysql中唯一约束限定的字段的值可以有多个null(null不算重复)
1
2
3
4
5
6
7
8
9
10
|
create table stu(
id int,
phone_number varchar(20) unique
);
alter table stu modify phone_number varchar(20) unique;
alter table stu drop index phone_number;
|
注意一下这里的删除约束使用的是drop,和非空约束的删除不同。
主键约束
primary key,主键约束
注意:
- 主键约束的含义是,表示该字段非空且唯一
- 一张表只能有一个字段为主键
- 主键就是表中记录的唯一标识
1
2
3
4
5
6
7
8
9
|
create table stu(
id int primary key,
name varchar(20)
);
alter table stu modify id int primary key;
alter table stu drop primary key;
|
自动增长
自动增长:如果某一字段是数值类型的,使用auto_increment可以来完成字段值的自动增长(自动+1)。
(以后也可在navicat上操作,不用输入命令行)
1
2
3
4
5
6
7
8
9
|
create table stu(
id int primary key auto_increment,
name varchar(20)
);
alter table stu modify id int auto_increment;
alter table stu modify id int;
|
外键约束
(详细讲解)
外键约束,foreign key,让表与表之间产生关系,从而保证数据的准确性。
1
2
3
4
5
6
7
8
9
10
11
|
create table 表名(
字段列表
...
外键字段
constraint 外键名称 foreign key(外键字段名称) references 主表名称(主表字段名称)
);
alter table 表名 add constraint 外键名称 foreign key(外键字段名称) references 主表名称(主表字段名称);
alter table 表名 drop foreign key 外键名称;
|
例子:
1
2
3
4
5
6
7
8
9
10
11
|
create table emp2(
id int primary key auto_increment,
name varchar(20),
dep_id int,
constraint emp2_dep_fk foreign key(dep_id) references dep(id)
);
alter table emp2 add constraint emp2_dep_fk foreign key(dep_id) references dep(id);
alter table emp2 drop foreign key emp2_dep_fk;
|



级联操作
相关讲解
相关文章
级联操作分为级联更新 on update cascade和级联删除 on delete cascade
- 级联更新: 当主表的记录(一般是主键值)发生更新时,从表自动更新自己的外键值。
- 级联删除:当主表的关联记录被删除时,从表会自动删除与主表删除记录相关联的记录。
1
2
|
alter table 表名 add constraint 外键名称 foreign key(外键字段名称) references 主表名称(主表字段名称) on update cascade [on delete cascade];
|
例子:
1
2
|
alter table emp2 add constraint emp2_dep_fk foreign key(dep_id) references dep(id) on update cascade on delete cascade;
|

添加级联更新和级联删除后,我们在dep表中删除id为1的数据,在emp2表中dep_id为1的数据也会随之删除,在dep表中修改id为2的数据改为1,在emp2表中dep_id为2的数据也会随之改为1。
级联操作以后要谨慎使用
多表关系
多表之间的关系有:一对一(了解),一对多(多对一),多对多
- 一对一:如人和身份证(一个人只有一个身份证,一个身份证只能对应一个人)
- 一对多(多对一):如部门和员工(一个部门有多个员工,一个员工只能对应一个部门)
- 多对多:如学生和课程(一个学生可以选择多个课程,一个课程也可以被多个学生选择)
关系实现:
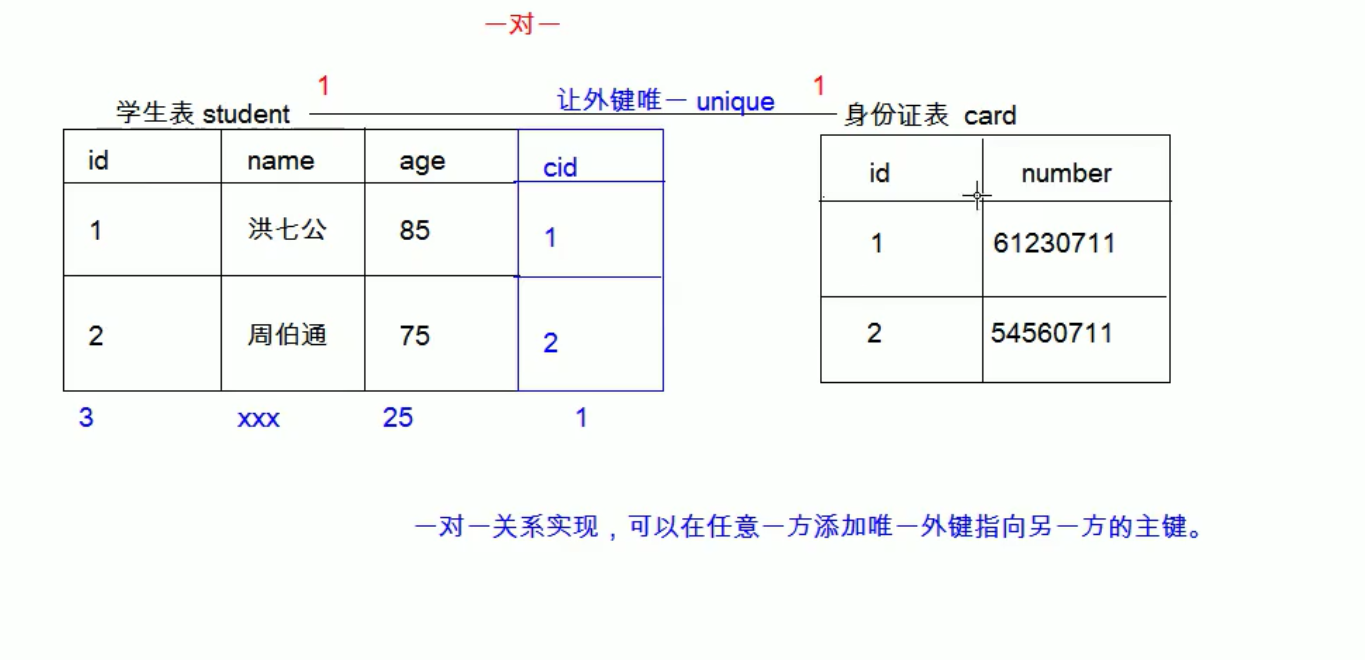
- 一对一(了解):可以在任意一方添加唯一外键指向另一方的主键,且让外键唯一(加唯一约束)
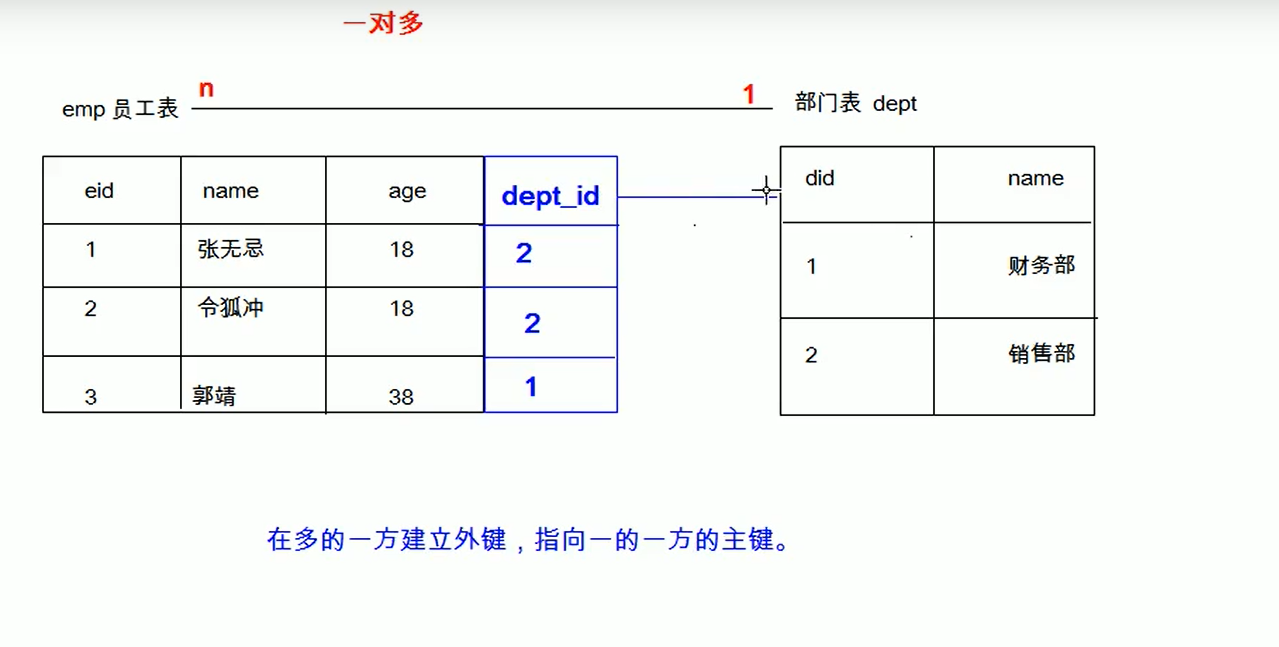
- 一对多(多对一):在多的一方建立外键,指向一的一方的主键
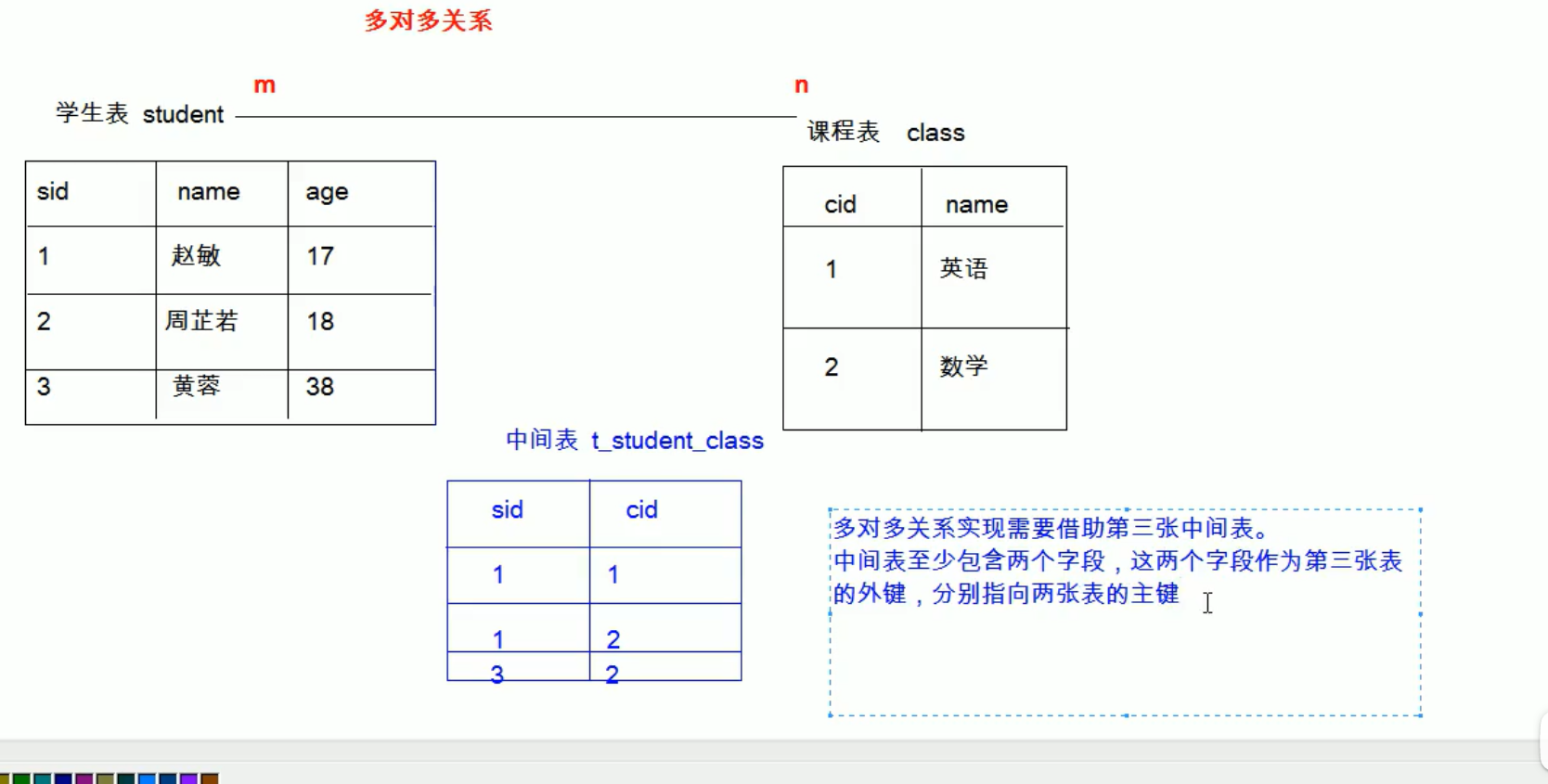
- 多对多:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
一对多:
视频链接
多对多:
视频讲解
一对一(了解):
视频讲解
案例
视频讲解
案例分析:

(在这个案例中,我们**通过navicat来图形化创建表以及相关约束**)
根据上述分析,我们先创建分类表tab_category,设置cname的唯一约束如下:
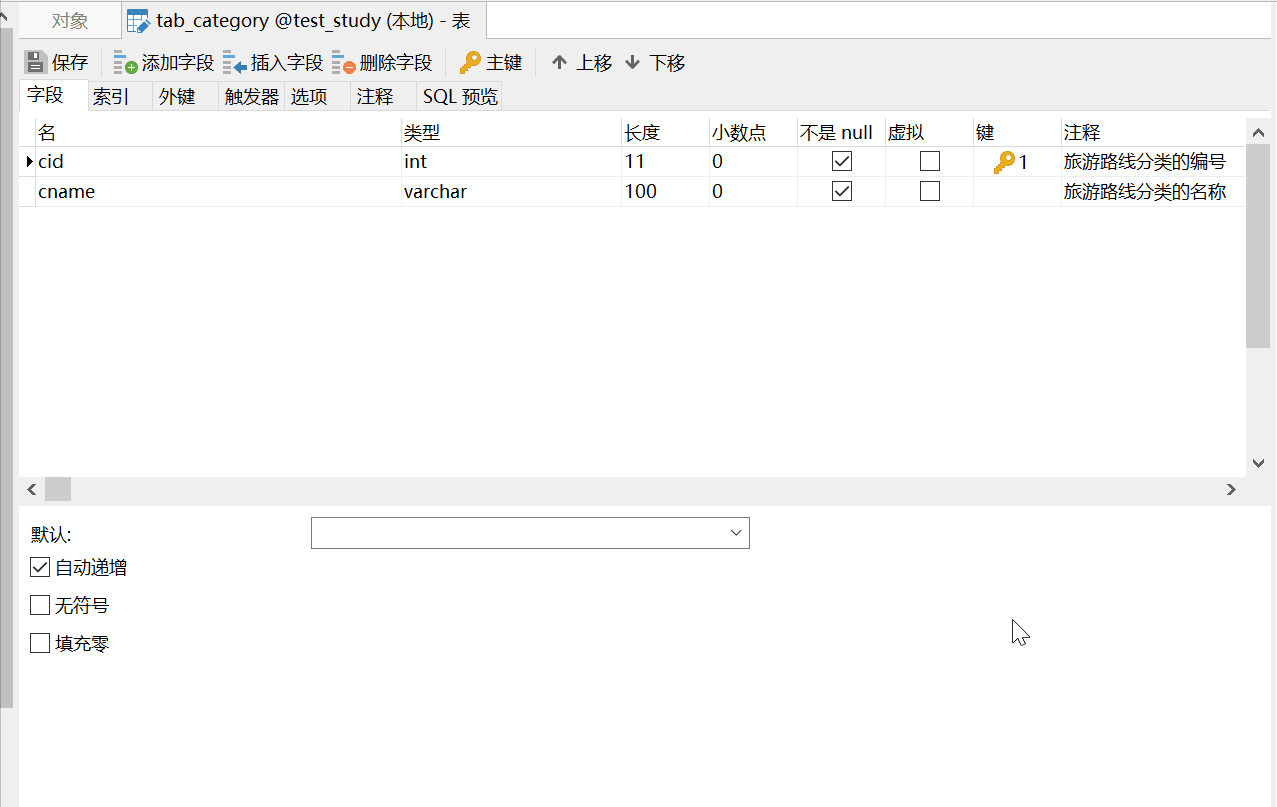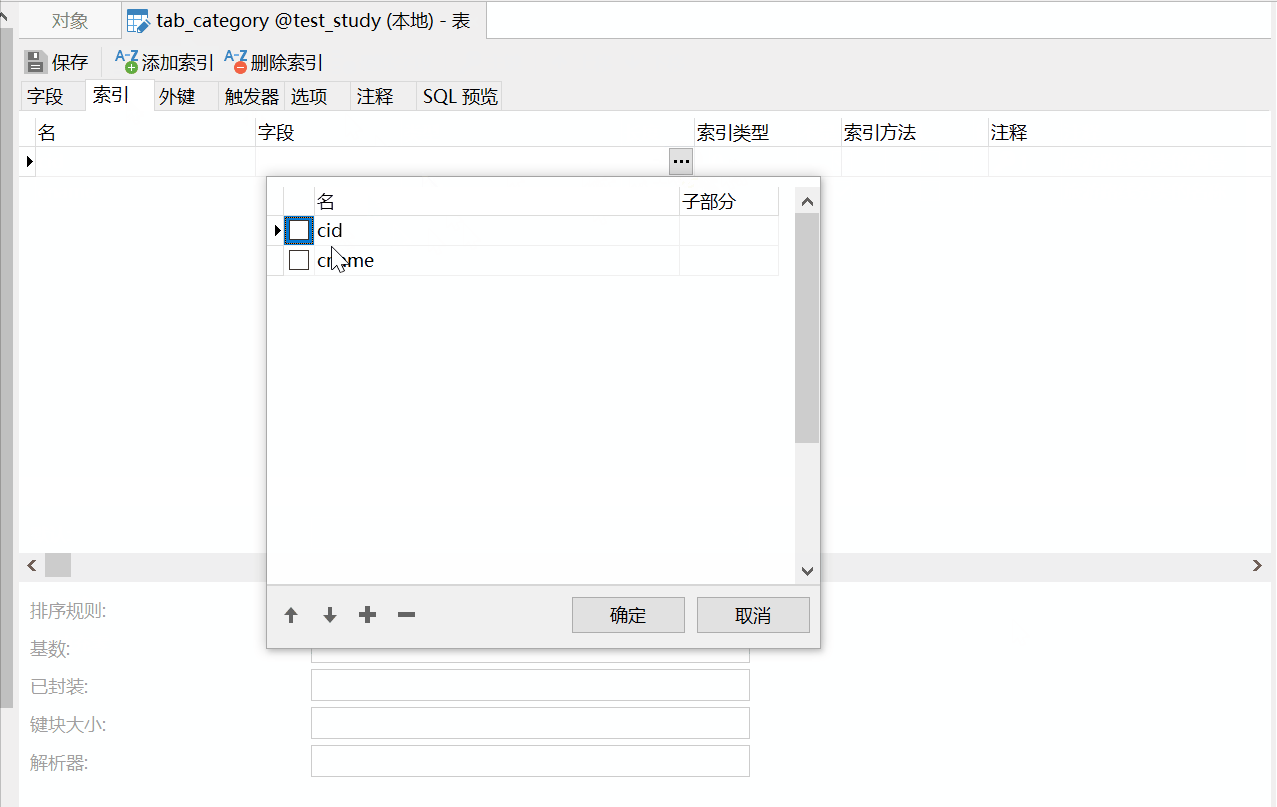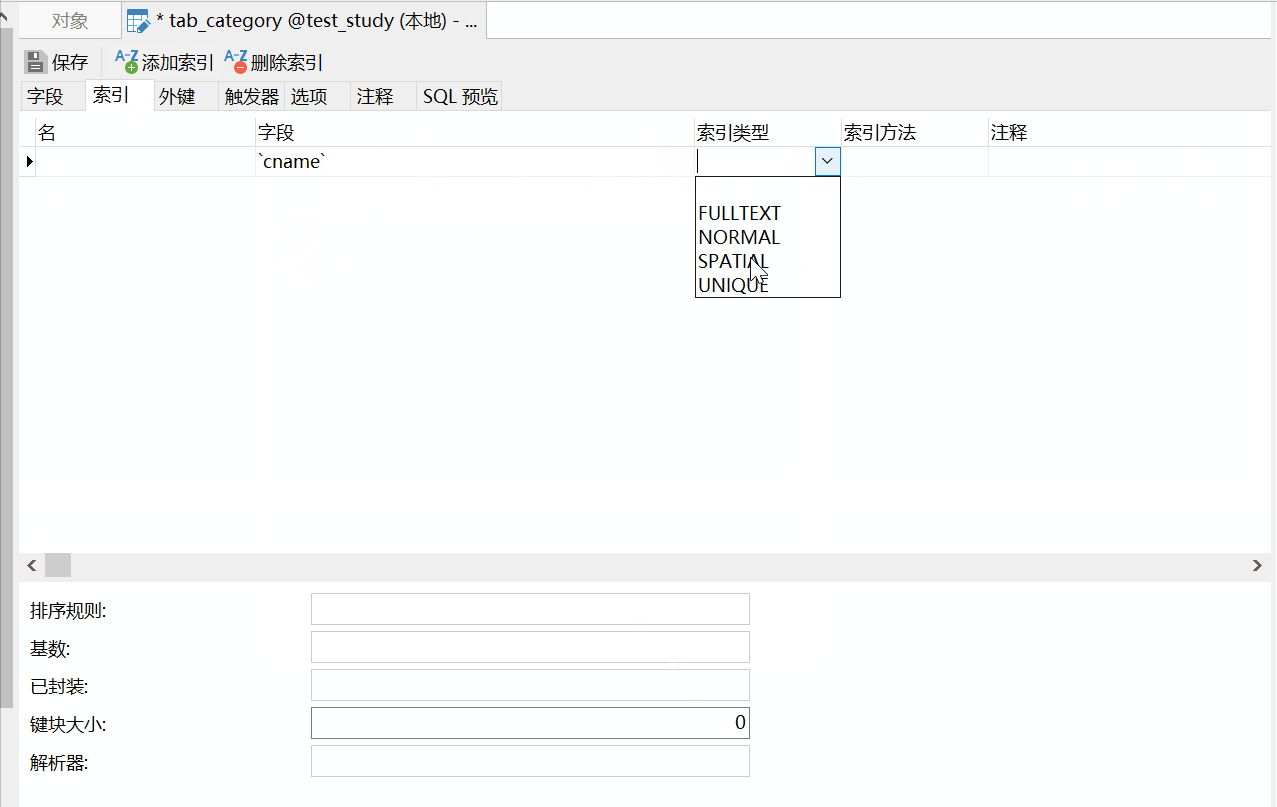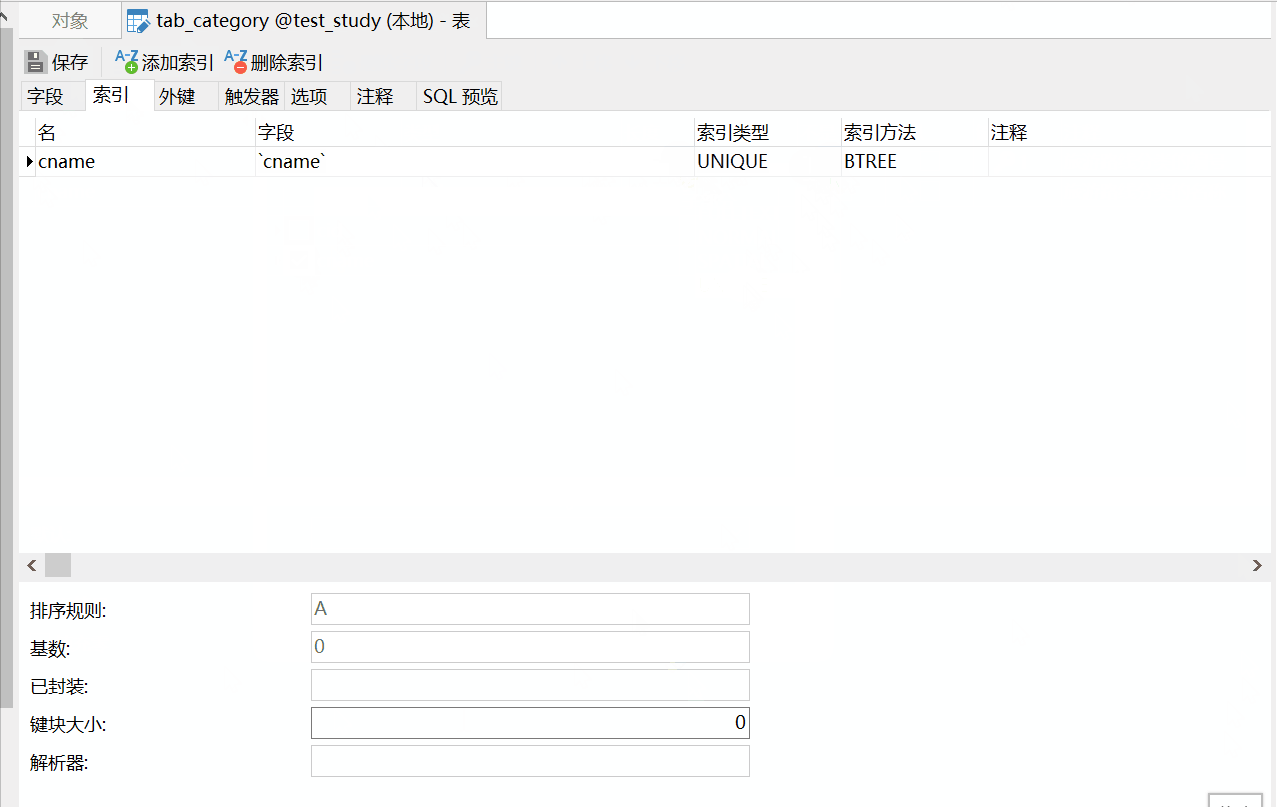
创建tab_category的sql语句为(由navicat导出):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `tab_category`;
CREATE TABLE `tab_category` (
`cid` int(11) NOT NULL AUTO_INCREMENT COMMENT '旅游路线分类的编号',
`cname` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '旅游路线分类的名称',
PRIMARY KEY (`cid`) USING BTREE,
UNIQUE INDEX `cname`(`cname`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
|
然后再创建tab_route表,路线线路表:
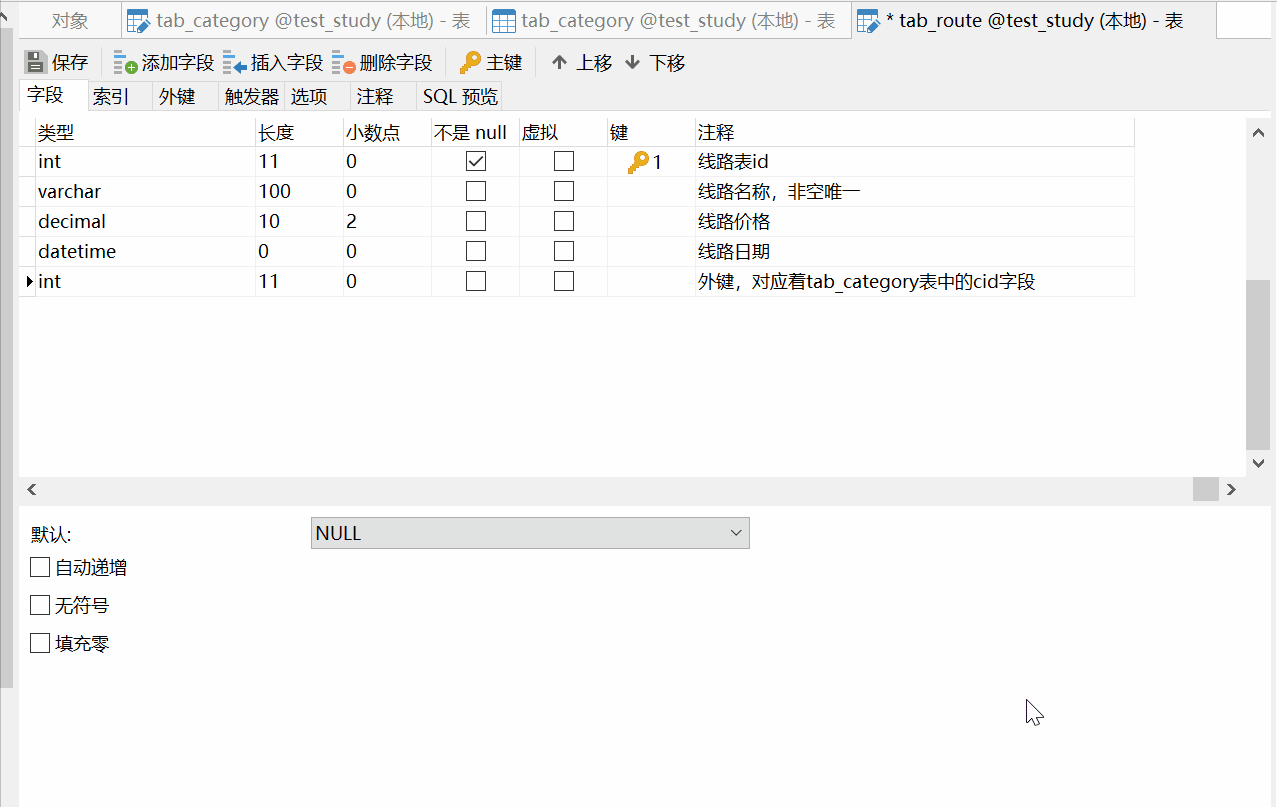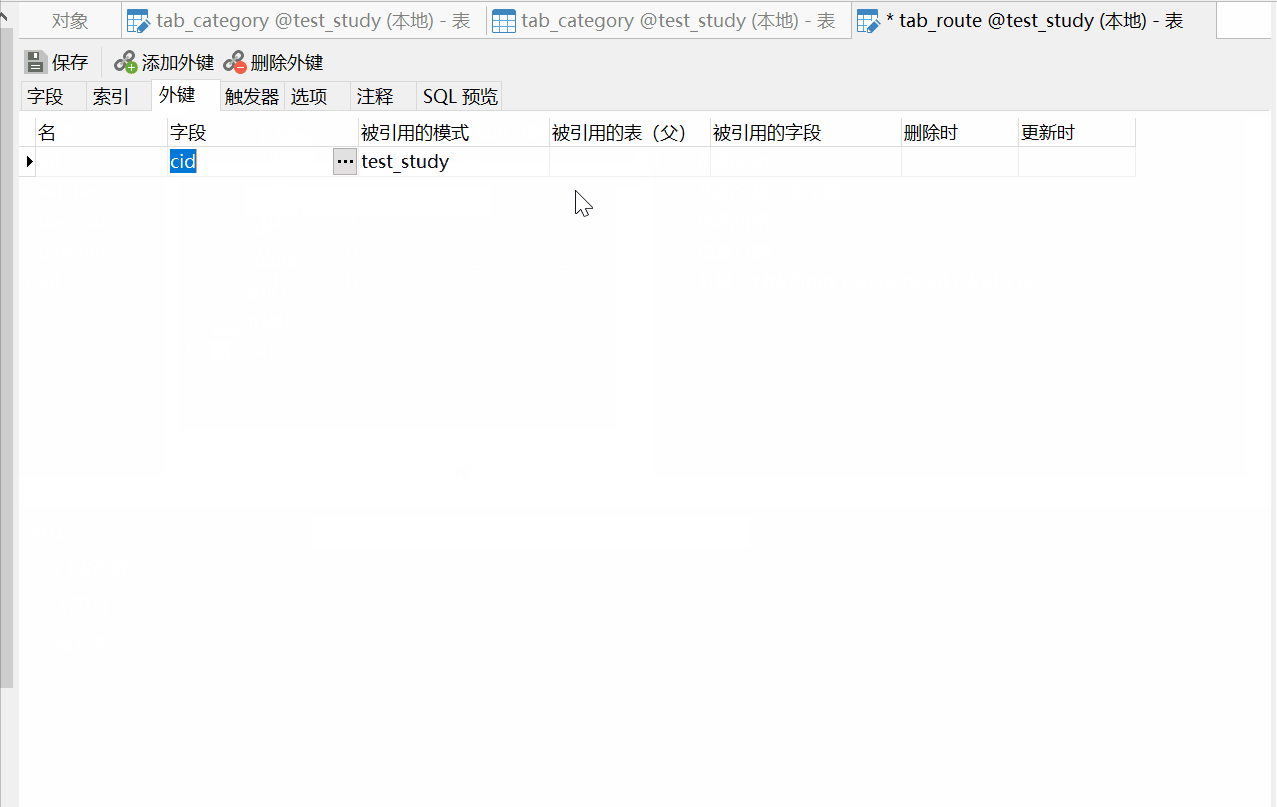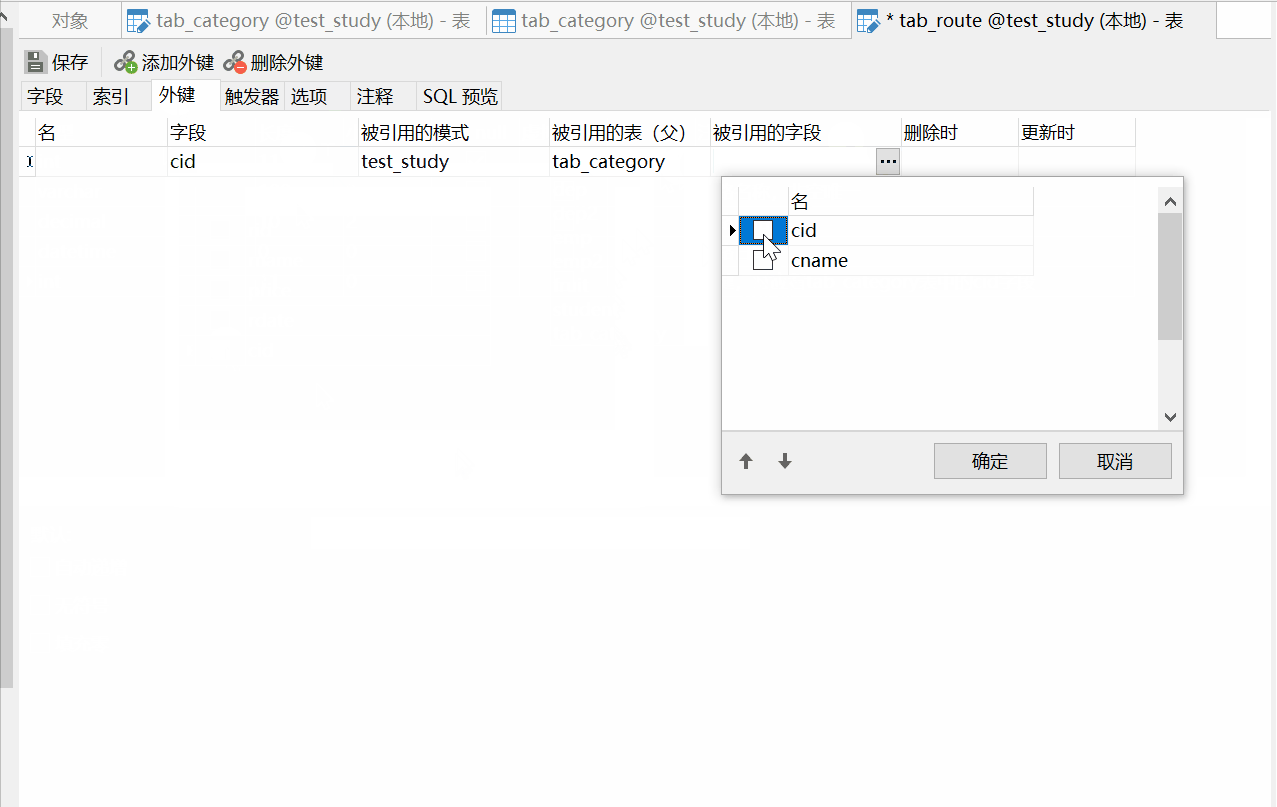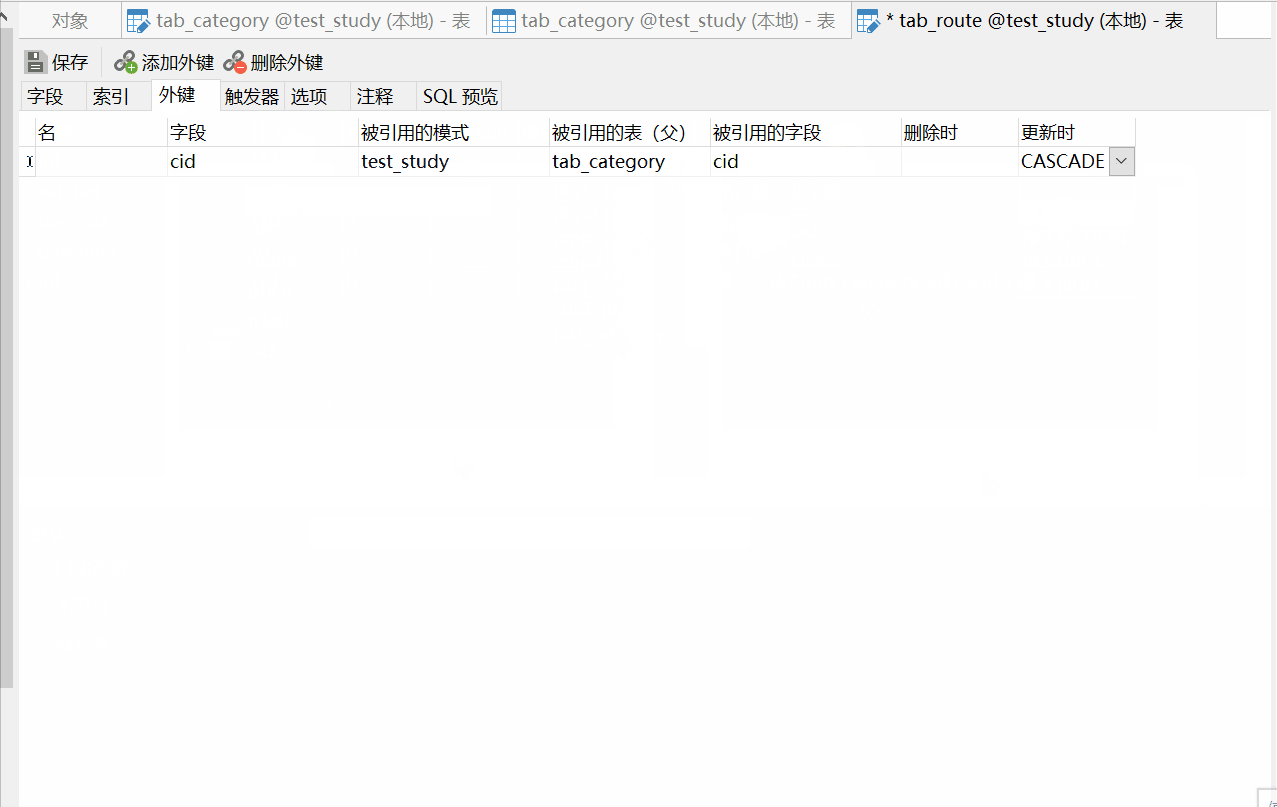
在后面的删除时和更新时的选项,表示级联相关操作:
- 删除时不选,则默认为RESTRICT(限制),即父表不能删除或更新一个已经被子表数据引用的记录
- 更新时选择CASCADE(级联),即父表的操作,对应子表关联的数据也跟着被删除
- set null:置空模式,父表的操作之后,子表对应的数据(外键字段)被置空
- NO ACTION,顾名思义就是父表的操作,对应子表关联的数据不发生变化
创建tab_route的SQL语句为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `tab_route`;
CREATE TABLE `tab_route` (
`rid` int(11) NOT NULL AUTO_INCREMENT COMMENT '线路表id',
`rname` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '线路名称,非空唯一',
`price` decimal(10, 2) NULL DEFAULT NULL COMMENT '线路价格',
`rdate` datetime(0) NULL DEFAULT NULL COMMENT '线路日期',
`cid` int(11) NULL DEFAULT NULL COMMENT '外键,对应着tab_category表中的cid字段',
PRIMARY KEY (`rid`) USING BTREE,
INDEX `cid`(`cid`) USING BTREE,
CONSTRAINT `tab_route_ibfk_1` FOREIGN KEY (`cid`) REFERENCES `tab_category` (`cid`) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
|
然后我们创建用户表tab_user如下,并为username字段添加唯一约束:
对应sql语句为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `tab_user`;
CREATE TABLE `tab_user` (
`uid` int(11) NOT NULL COMMENT '用户id作主键',
`username` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名称',
`password` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户密码',
PRIMARY KEY (`uid`) USING BTREE,
UNIQUE INDEX `username`(`username`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
|
先创建user2route表,然后设置外键,这里还可以通过ER视图来创建外键:
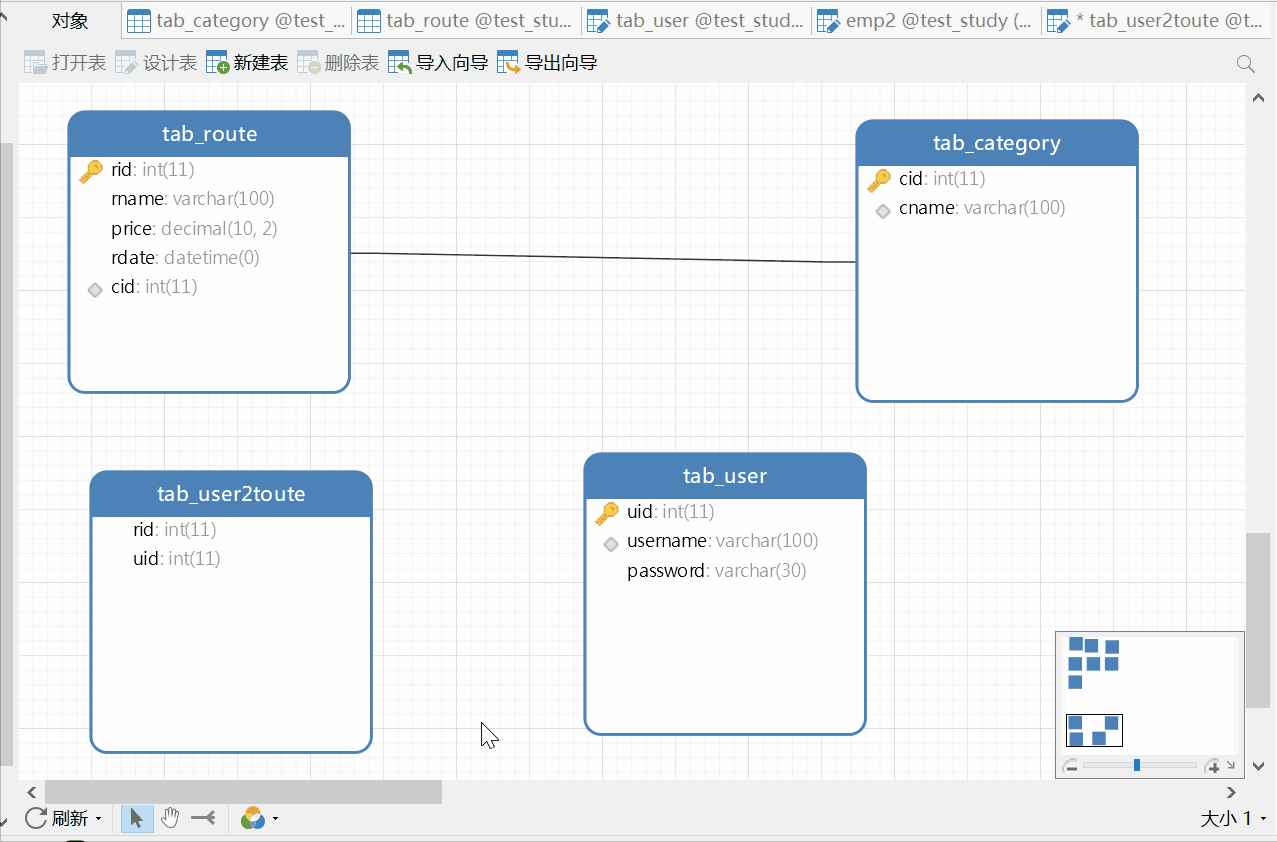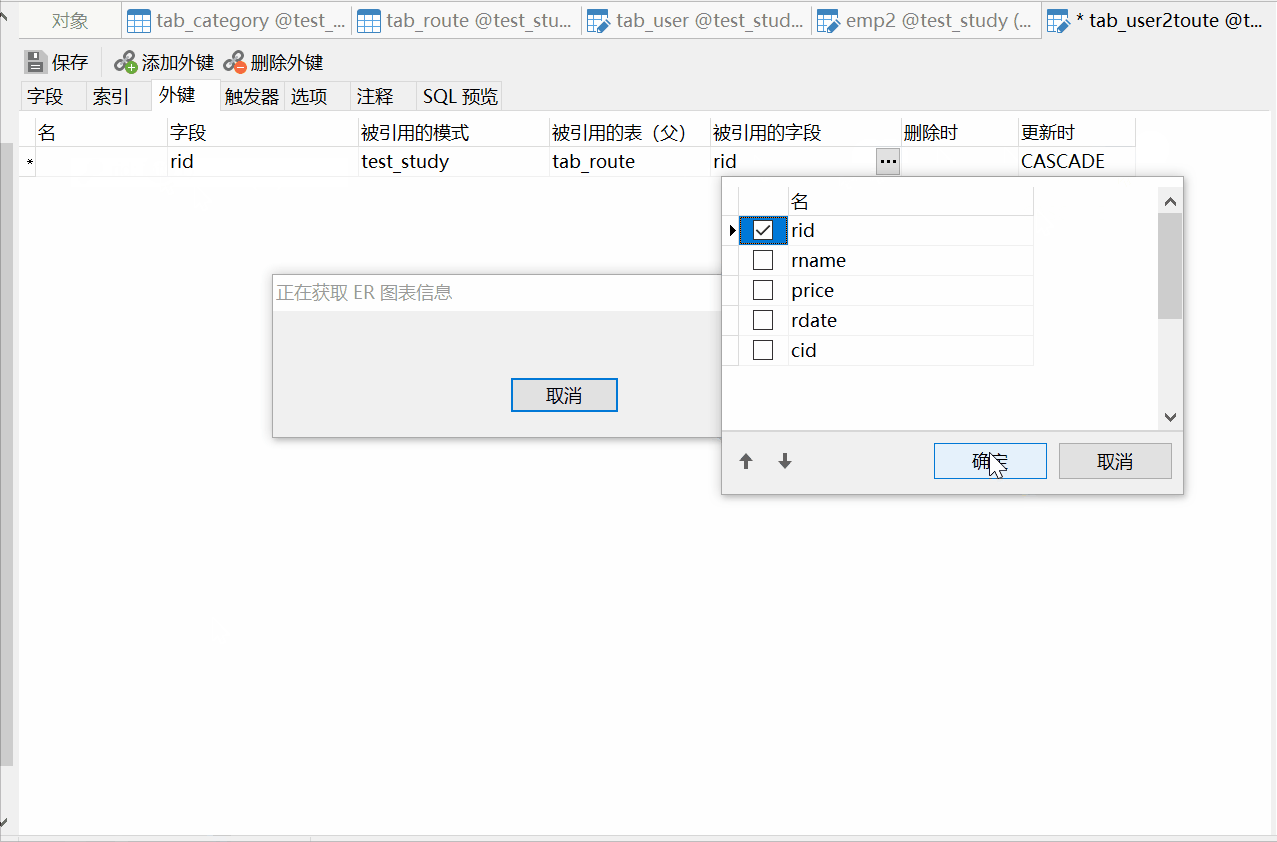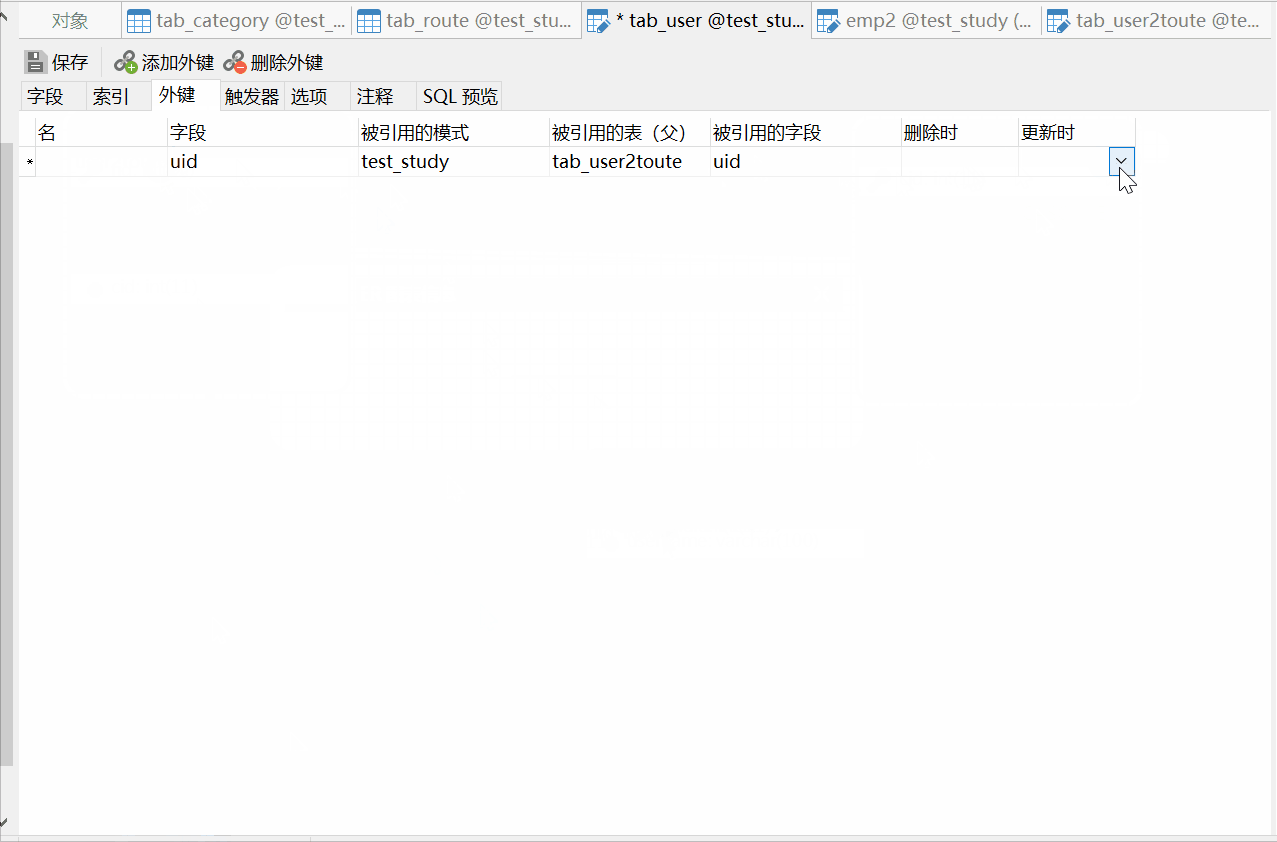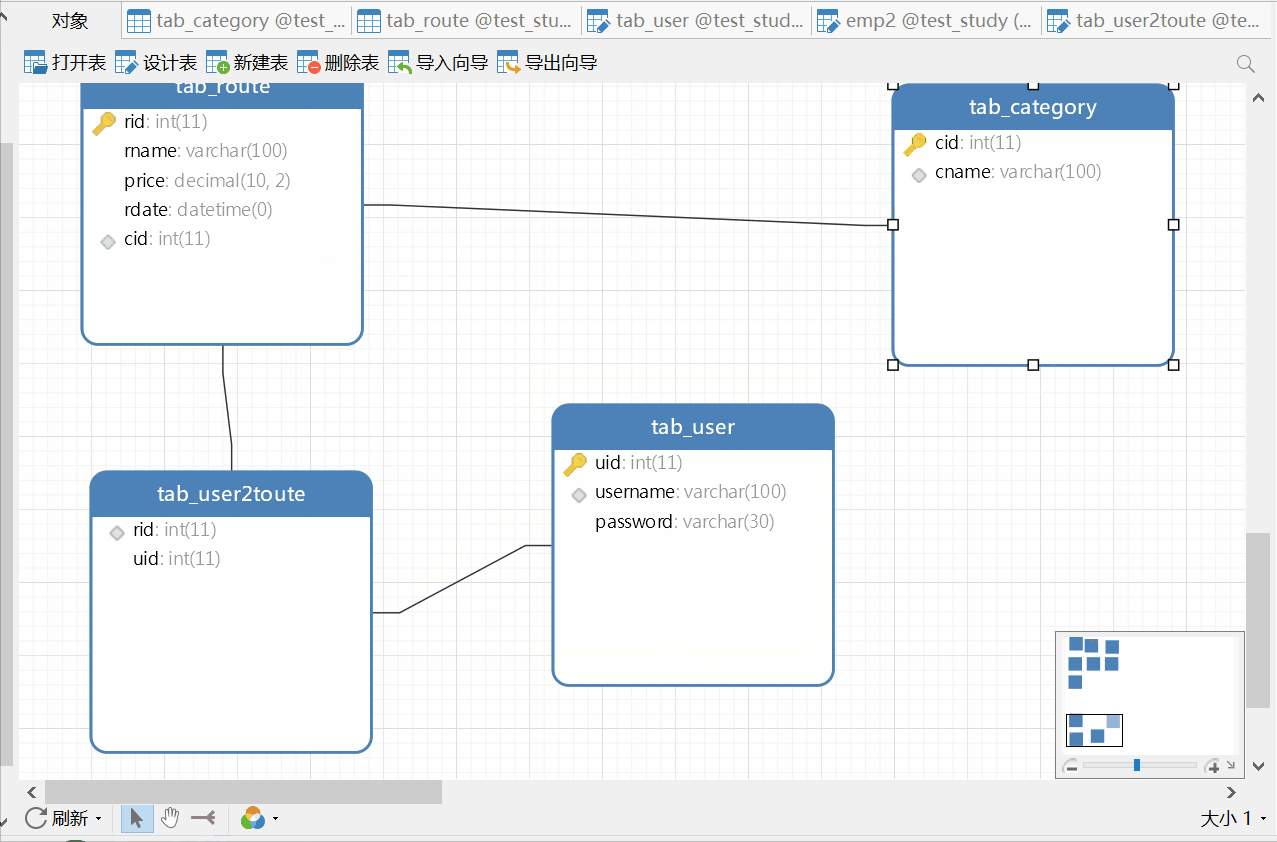
对应sql语句为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `tab_user2toute`;
CREATE TABLE `tab_user2toute` (
`rid` int(11) NOT NULL COMMENT '对应tab_route表的主键rid',
`uid` int(11) NOT NULL COMMENT '对应tab_user表的主键uid',
INDEX `rid`(`rid`) USING BTREE,
INDEX `uid`(`uid`) USING BTREE,
CONSTRAINT `tab_user2toute_ibfk_1` FOREIGN KEY (`rid`) REFERENCES `tab_route` (`rid`) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
|
范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
数据库范式(1NF 2NF 3NF BCNF)详解
三大范式视频讲解
第一范式(1NF)
第一范式(1NF):每一列都是不可分割的原子数据项
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。
简而言之,第二范式(2NF)就是非主属性完全依赖于主键。(第二范式(2NF)属性完全依赖于主键 [ 消除部分子函数依赖 ])
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF的基础上消除非主属性对主码的部分函数依赖)
几个概念:
- 函数依赖:A–>B,如果通过A属性(属性组)的值,可以确定唯一B属性的值,则称B依赖于A (例如:学号–>姓名,(学号,课程名称)–>分数)
- 完全函数依赖:A–>B,如果A是一个属性组,则要确定B属性的值需要依赖A属性组中所有的属性值 (例如:(学号,课程名称)–>分数)
- 部分函数依赖:A–>B,如果A是一个属性组,则要确定B属性的值需要依赖A属性组中部分的属性值即可 (例如:(学号,课程名称)–>姓名)
- 传递函数依赖:A–>B,B–>C,如果通过A属性(属性组)的值可以确定唯一B属性(属性组)的值,在B属性(属性组)的值可以确定唯一C属性的值,则称C传递函数依赖于A (例如:学号–>系名,系名–>系主任)
- 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码 (例如:在一个表中有以下字段:姓名、性别、年龄、身份证id,那么身份证id即为这个表的码)
- 主属性:码属性中的所有属性
- 非主属性:除去码属性中的所有属性
第三范式(3NF)
在2NF的基础上,任何非主属性不依赖与其他主属性(在2NF基础上消除传递依赖)
第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。简而言之,第三范式就是属性不依赖于其它非主属性。
数据库的备份和还原
相关文章
命令行,语法为:
1
2
3
4
|
mysqldump -u用户名 -p密码 数据库名称 > 保存的路径
source 文件路径
|
图形化界面:
Navicat Premium实现mysql数据库备份/还原
通过Navicat进行Mysql数据库自动备份与还原



