x86处理器架构
汇编笔记是根据C语言中文网完成的
CPU处理器架构和工作原理浅析
基本微机设计
下图给出了假想机的基本设计。中央处理单元(CPU)是进行算术和逻辑操作的部件,包含了有限数量的存储位置——寄存器(register),一个高频时钟、一个控制单元和一个算术逻辑单元。

其中:
- 时钟 (clock) 对 CPU 内部操作与系统其他组件进行同步。
- 控制单元 (control unit, CU) 协调参与机器指令执行的步骤序列。
- 算术逻辑单元 (arithmetic logic unit, ALU) 执行算术运算,如加法和减法,以及逻辑运算,如 AND(与)、OR(或)和 NOT(非)。
CPU 通过主板上 CPU 插座的引脚与计算机其他部分相连。大部分引脚连接的是数据总线、控制总线和地址总线。
内存存储单元 (memory storage unit) 用于在程序运行时保存指令与数据。它接受来自 CPU 的数据请求,将数据从随机存储器 (RAM) 传输到 CPU,并从 CPU 传输到内存。
由于所有的数据处理都在 CPU 内进行,因此保存在内存中的程序在执行前需要被复制到 CPU 中。程序指令在复制到 CPU 时,可以一次复制一条,也可以一次复制多条。
总线 (bus) 是一组并行线,用于将数据从计算机一个部分传送到另一个部分。一个计算机系统通常包含四类总线:数据类、I/O 类、控制类和地址类。
数据总线 (data bus) 在 CPU 和内存之间传输指令和数据。I/O 总线在 CPU 和系统输入 / 输出设备之间传输数据。控制总线 (control bus) 用二进制信号对所有连接在系统总线上设备的行为进行同步。当前执行指令在 CPU 和内存之间传输数据时,地址总线 (address bus) 用于保持指令和数据的地址。
时钟与 CPU 和系统总线相关的每一个操作都是由一个恒定速率的内部时钟脉冲来进行同步。机器指令的基本时间单位是机器周期 (machine cycle) 或时钟周期 (clock cycle)。
一个时钟周期的时长是一个完整时钟脉冲所需要的时间。下图中,一个时钟周期被描绘为两个相邻下降沿之间的时间:

时钟周期持续时间用时钟速度的倒数来计算,而时钟速度则用每秒振荡数来衡量。例如,一个每秒振荡 10 亿次 (1GHz) 的时钟,其时钟周期为 10 亿分之 1 秒 (1 纳秒 )。
执行一条机器指令最少需要 1 个时钟周期,有几个需要的时钟则超过了 50 个(比如 8088 处理器中的乘法指令)。由于在 CPU、系统总线和内存电路之间存在速度差异,因此,需要访问内存的指令常常需要空时钟周期,也被称为等待状态 (wait states)。
指令执行周期
一条机器指令不会神奇地一下就执行完成。CPU 在执行一条机器指令时,需要经过一系列预先定义好的步骤,这些步骤被称为指令执行周期 (instruction execution cycle)。
假设现在指令指针寄存器中已经有了想要执行指令的地址,下面就是执行步骤:
- CPU 从被称为指令队列 (instruction queue) 的内存区域取得指令,之后立即增加指令指针的值。
- CPU 对指令的二进制位模式进行译码。这种位模式可能会表示该指令有操作数(输入值)。
- 如果有操作数,CPU 就从寄存器和内存中取得操作数。有时,这步还包括了地址计算。
- 使用步骤 3 得到的操作数,CPU 执行该指令。同时更新部分状态标志位,如零标志 (Zero)、进位标志 (Carry) 和溢出标志 (Overflow)。
- 如果输出操作数也是该指令的一部分,则 CPU 还需要存放其执行结果。
通常将上述听起来很复杂的过程简化为三个步骤:取指 (Fetch)、译码 (Decode) 和执行 (Execute)。操作数 (operand) 是指操作过程中输入或输出的值。例如,表达式 Z=X+Y 有两个输入操作数 (X 和 Y),—个输岀操作数 (Z)。
下图是一个典型 CPU 中的数据流框图。该图表现了在指令执行周期中相互交互部件之间的关系。在从内存读取程序指令之前,将其地址放到地址总线上。然后,内存控制器将所需代码送到数据总线上,存入代码高速缓存 (code cache)。指令指针的值决定下一条将要执行的指令。指令由指令译码器分析,并产生相应的数值信号送往控制单元,其协调 ALU 和浮点单元。虽然图中没有画出控制总线,但是其上传输的信号用系统时钟协调不同 CPU 部件之间的数据传输。

读取内存
作为一个常见现象,计算机从内存读取数据比从内部寄存器读取速度要慢很多。这是因为从内存读取一个值,需要经过下述步骤:
- 将想要读取的值的地址放到地址总线上。
- 设置处理器 RD(读取)引脚(改变 RD 的值)。
- 等待一个时钟周期给存储器芯片进行响应。
- 将数据从数据总线复制到目标操作数。
上述每一步常常只需要要一个时钟周期,但是和CPU 寄存器相比,这个速度还是慢了,因为访问寄存器一般只需要 1 个时钟周期。
CPU 设计者提出了一个减少读写内存时间的方法:将大部分近期使用过的指令和数据存放在高速存储器 cache 中。
x86 系列中的 cache 存储器有两种类型:一级 cache(或主 cache)位于 CPU 上;二级 cache (或次 cache)速度略慢,通过高速数据总线与 CPU 相连。这两种 cache 以最佳方式一 起工作。
加载并执行程序
在程序执行之前,需要用一种工具程序将其加载到内存,这种工具程序称为程序加载器 (program loader)。加载后,操作系统必须将 CPU 向程序的入口,即程序开始执行的地址。
32位x86处理器架构
本节重点讲解了 32 位 x86 处理器的基本架构特点。这些处理器包括了 Intel IA-32 系列中的成员和所有 32 位 AMD 处理器。
操作模式
x86 处理器有三个主要的操作模式:保护模式、实地址模式和系统管理模式;以及一个子模式:虚拟 8086 (virtual-8086) 模式,这是保护模式的特殊情况。
基本执行环境
1.地址空间
在 32 位保护模式下,一个任务或程序最大可以寻址 4GB 的线性地址空间。从 P6 处理器开始,一种被称为扩展物理寻址 (extended physical addressing) 的技术使得可以被寻址的物理内存空间增加到 64GB。
与之相反,实地址模式程序只能寻址 1MB 空间。如果处理器在保护模式下运行多个虚拟 8086 程序,则每个程序只能拥有自己的 1MB 内存空间。
2. 基本程序执行寄存器
寄存器是直接位于 CPU 内的高速存储位置,其设计访问速度远高于传统存储器。例如,当一个循环处理为了速度进行优化时,其循环计数会保留在寄存器中而不是变量中。
下图展示的是基本程序执行寄存器(basic program execution registers)。8 个==通用寄存器,6 个段寄存器==,一个处理器状态标志寄存器(EFLAGS),和一 个指令指针寄存器(EIP)。

通用寄存器
通用寄存器主要用于算术运算和数据传输。如下图所示,EAX 寄存器的低 16 位在使用时可以用 AX 表示。

一些寄存器的组成部分可以处理 8 位的值。例如,AX 寄存器的高 8 位被称为 AH,而低 8 位被称为 AL。同样的重叠关系也存在于 EAX、EBX、ECX 和 EDX 寄存器中:
| 32 位 | 16 位 | 8 位(高) | 8 位(低) |
|---|---|---|---|
| EAX | AX | AH | AL |
| EBX | BX | BH | BL |
| ECX | CX | CH | CL |
| EDX | DX | DH | DL |
其他通用寄存器只能用 32 位或 16 位名称来访问,如下表所示:
| 32 位 | 16 位 | 32 位 | 16 位 |
|---|---|---|---|
| ESI | SI | EBP | BP |
| EDI | DI | ESP | SP |
特殊用法
某些通用寄存器有特殊用法:
- 乘除指令默认使用EAX。它常常被称为扩展累加器(extended accumulator)寄存器。
- CPU 默认==使用 ECX 为循环计数器==。
- ESP 用于寻址堆栈(一种系统内存结构)数据。它极少用于一般算术运算和数据传输,通常被称为扩展堆栈指针(extended stack pointer)寄存器。
- ESI 和 EDI 用于高速存储器传输指令,有时也被称为扩展源变址(extended source index)寄存器和扩展目的变址(extended destination index)寄存器。
- 高级语言通过 EBP 来引用堆栈中的函数参数和局部变量。除了高级编程,它不用于一般算术运算和数据传输。它常常被称为扩展帧指针(extended frame pointer)寄存器。
段寄存器
实地址模式中,16 位段寄存器表示的是预先分配的内存区域的基址,这个内存区域称为段。保护模式中,段寄存器中存放的是段描述符表指针。一些段中存放程序指令(代码),其他段存放变量(数据),还有一个堆栈段存放的是局部函数变量和函数参数。
指令指针
指令指针(EIP)寄存器中包含下一条将要执行指令的地址。某些机器指令能控制 EIP,使得程序分支转向到一个新位置。
EFLAGS 寄存器
EFLAGS (或 Flags)寄存器包含了独立的二进制位,用于控制 CPU 的操作,或是反映一些 CPU 操作的结果。有些指令可以测试和控制这些单独的处理器标志位。
设置标志位时,该标识位 =1;清除(或重置)标识位时,该标志位 =0。
控制标志位
控制标志位控制 CPU 的操作。例如,它们能使得 CPU 每执行一条指令后进入中断;在侦测到算术运算溢出时中断执行;进入虚拟 8086 模式,以及进入保护模式。
程序能够通过设置 EFLAGS 寄存器中的单独位来控制 CPU 的操作,比如,方向标志位和中断标志位。
状态标志位
状态标志位反映了 CPU 执行的算术和逻辑操作的结果。其中包括:溢出位、符号位、零标志位、辅助进位标志位、奇偶校验位和进位标志位。下述说明中,标志位的缩写紧跟在标志位名称之后:
- 进位标志位(CF),与目标位置相比,无符号算术运算结果太大时,设置该标志位。
- 溢出标志位(OF),与目标位置相比,有符号算术运算结果太大或太小时,设置该标志位。
- 符号标志位(SF),算术或逻辑操作产生负结果时,设置该标志位。
- 零标志位(ZF),算术或逻辑操作产生的结果为零时,设置该标志位。
- 辅助进位标志位(AC),算术操作在 8 位操作数中产生了位 3 向位 4 的进位时,设置该标志位。
- 奇偶校验标志位(PF),结果的最低有效字节包含偶数个 1 时,设置该标志位,否则,清除该标志位。一般情况下,如果数据有可能被修改或损坏时,该标志位用于进行 错误检测。
3.MMX 寄存器
在实现高级多媒体和通信应用时,MMX 技术提高了 Intel 处理器的性能。8 个 64 位 MMX 寄存器支持称为 SIMD(单指令,多数据,Single-Instruction,Multiple-Data)的特殊指令。
顾名思义,MMX 指令对 MMX 寄存器中的数据值进行并行操作。虽然,它们看上去是独立的寄存器,但是 MMX 寄存器名实际上是浮点单元中使用的同样寄存器的别名。
4.XMM 寄存器
x86 结构还包括了 8 个 128 位 XMM 寄存器,它们被用于 SIMD 流扩展指令集。
浮点单元:浮点单元(FPU, floating-point unit)执行高速浮点算术运算。之前为了这个目的,需要一个独立的协处理器芯片。从 Intel486 处理器开始,FPU 已经集成到主处理器芯片上。
FPU 中有 8 个浮点数据寄存器,分别命名为 ST(0),ST(1),ST(2),ST(3),ST(4), ST(5), ST (6)和 ST(7)。其他控制寄存器和指针寄存器如下图所示。

64位x86-64处理器架构
当处理器运行于本机 64 位模式时,是不支持 16 位实模式或虚拟 8086 模式的。(在传统模式(legacy mode)下,还是支持 16 位编程,但是在 Microsoft Windows 64 位版本中不可用。)
Intel 64 架构引入了一个新模式,称为 IA-32e。从技术上看,这个模式包含两个子模式:兼容模式(compatibility mode)和 64 位模式(64-bit mode)。不过它们常常被看做是模式而不是子模式。
64位可用寄存器如下表:
| 操作数大小 | 可用寄存器 |
|---|---|
| 8 位 | AL、BL、CL、DL、DIL、SIL、BPL、SPL、R8L、R9L、R10L、R11L、R12L、R13L、R14L、R15L |
| 16 位 | AX、BX、CX、DX、DI、SI、BP、SP、R8W、R9W、R10W、R11W、R12W、R13W、R14W、R15W |
| 32 位 | EAX、EBX、ECX、EDX、EDI、ESI、EBP、ESP、R8D、R9D、R10D、R11D、R12D、R13D、R14D、R15D |
| 64 位 | RAX、RBX、RCX、RDX、RDI、RSI、RBP、RSP、R8、R9、R10、R11、R12、R13、R14、R15 |
还有一些需要记住的细节:
- 64 位模式下,单条指令不能同时访问寄存器高字节,如 AH、BH、CH 和 DH,以及新字节寄存器的低字节(如 DIL)。
- 64 位模式下,32 位 EFLAGS 寄存器由 64 位 RFLAGS 寄存器取代。这两个寄存器共享低 32 位,而 RFLAGS 的高 32 位是不使用的。
- 32 位模式和 64 位模式具有相同的状态标志。
x86计算机组件
主板
主板是微型计算机的心脏,它是一个平面电路板,其上集成了 CPU、支持处理器(芯片组(chipset))、主存、输入输出接口、电源接口和扩展插槽。
各种组件通过总线即一组直接蚀刻在主板上的导线,进行互连。目前 PC 市场上有几十种主板,它们在扩展功能、集成部件和速度方面存在着差异。
内存
基于 Intel 的系统使用的是几种基础类型内存:只读存储器(ROM)、可擦除可编程只读存储器(EPROM)、动态随机访问存储器(DRAM)、静态 RAM (SRAM)、图像随机存储器(VRAM),和互补金属氧化物半导体(CMOS)RAM。
计算机I/O输入输出系统
由于计算机游戏与内存和 I/O 有着非常密切的关系,因此,它们推动计算机达到其最大性能。善于游戏编程的程序员通常很了解视频和音频硬件,并会优化代码的硬件特性。
I/O 访问层次
应用程序通常从键盘和磁盘文件读取输入,而将输出写到显示器和文件中。完成 I/O 不需要直接访问硬件——相反,可以调用操作系统的函数。I/O 有单个三个不同的访问层次:高级语言函数、操作系统、BIOS。
设备驱动程序
设备驱动程序允许操作系统与硬件设备和系统 BIOS 直接通信。例如,设备驱动程序可能接收来自 OS 的请求来读取一些数据,而满足该请求的方法是,通过执行设备固件中的代码,用设备特有的方式来读取数据。
设备驱动程序有两种安装方法:一种是在特定硬件设备连接到系统之前,或者设备已连接并且识别之后。对于后一种方法,OS 识别设备名称和签名,然后在计算机上定位并安装设备驱动软件。
现在,通过展示应用程序在屏幕上显示字符串的过程,来了解 I/O 层次结构如下图所示。
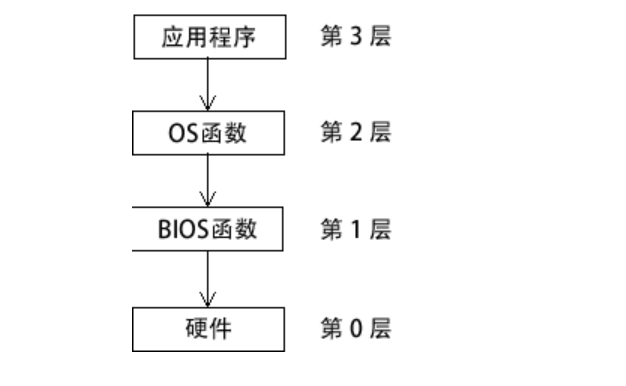
该过程包含以下步骤:
- 应用程序调用 HLL 库函数,将字符串写入标准输出。
- 库函数(第 3 层)调用操作系统函数,传递一个字符串指针。
- 操作系统函数(第 2 层)用循环的方法调用 BIOS 子程序,向其传递每个字符的 ASCII 码和颜色。操作系统调用另一个 BIOS 子程序,将光标移动到屏幕的下一个位置上。
- BIOS 子程序(第 1 层)接收一个字符,将其映射到一个特定的系统字体,并把该字符发送到与视频控制卡相连的硬件端口。
- 视频控制卡(第 0 层)为视频显示产生定时硬件信号,来控制光栅扫描并显示像素。
多层次编程
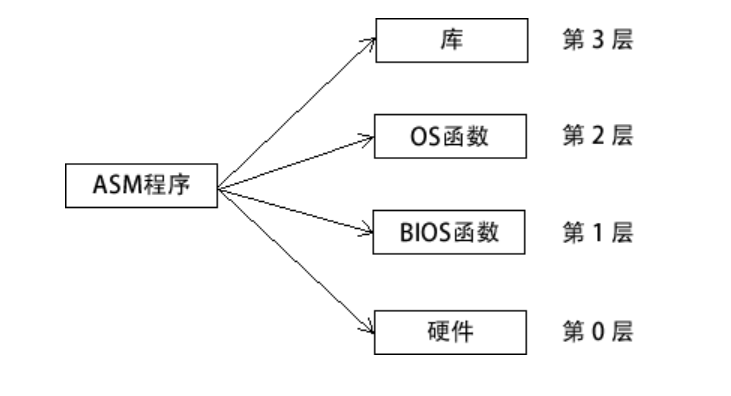
汇编语言程序在输入输出编程领域有着强大的能力和灵活性。它们可以从以下访问层次进行选择 (如下图所示):
- 第 3 层:调用库函数来执行通用文本 I/O 和基于文件的 I/O。
- 第 2 层:调用操作系统函数来执行通用文本 I/O 和基于文件的 I/O。如果 OS 使用了图形用户界面,它就能用与设备无关的方式来显示图形。
- 第 1 层:调用 BIOS 函数来控制设备具体特性,如颜色、图形、声音、键盘输入和底层磁盘 I/O。
- 第 0 层:从硬件端口发送和接收数据,对特定设备拥有绝对控制权。这个方式没有广泛用于各种硬件设备,因此不具可移植性。不同设备通常使用不同硬件端口,因此,程序代码必须根据每个设备的特定类型来进行定制。
如何进行权衡?控制与可移植性是最重要的。第 2 层(OS)工作在任何一个运行同样操作系统的计算机上。如果 I/O 设备缺少某些功能,那么 OS 将尽可能接近预期结果。第 2 层速度并不特别快,因为每个 I/O 调用在执行前,都必须经过好几个层次。
第 1 层(BIOS)在具有标准 BIOS 的所有系统上工作,但是在这些系统上不会产生同样的结果。例如,两台计算机可能会有不同分辨率的视频显示功能。在第 1 层上的程序员需要编写代码来检测用户的硬件设置,并调整输出格式来与之匹配。第 1 层的速度比第 2 层快,因为它与硬件之间只隔了一个层次。
第 0 层(硬件)与通用设备一起工作,如串行端口;或是与由知名厂商生产的特殊 I/O 设备一起工作。这个层次上的程序必须扩展它们的编码逻辑来处理 I/O 设备的变化。实模式的游戏程序就是最好的例子,因为它们常常需要取得计算机的控制权。第 0 层的程序执行速度与硬件一样快。
汇编笔记是根据C语言中文网完成的




