算法学习:链表
参考代码随想录:链表理论基础
关于链表这种数据结构,之前已经学习过了(笔记:线性表)。这里不再多说,直接看几个LeetCode上的题目。
移除链表元素
代码随想录:
单链表
经典的删除单链表的结点。不用多说什么,主需要注意两点:
-
dummyNode的使用
-
删除一个结点,那么我们要遍历到当前结点的前一个结点
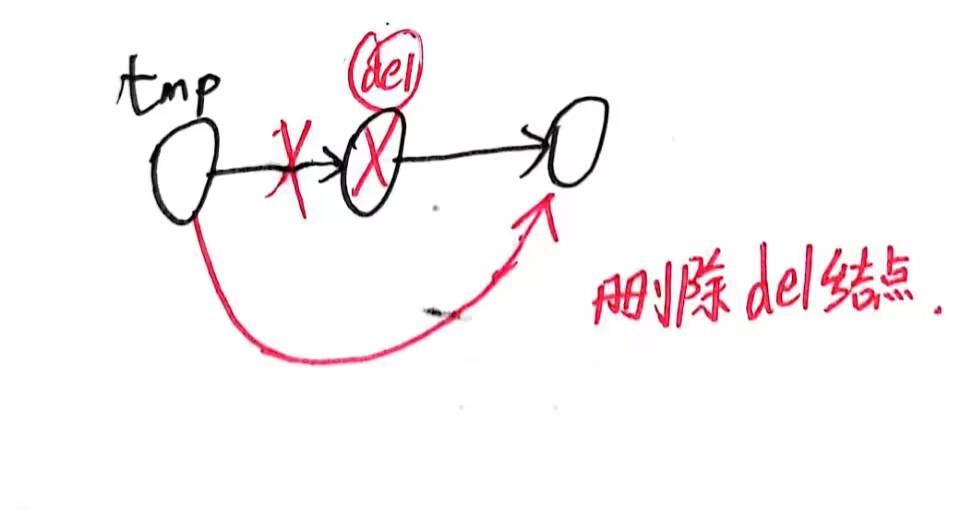
代码如下:
1 | func removeElements(head *ListNode, val int) *ListNode { |
(结合代码画一下草稿就搞懂了)
设计链表
代码随想录:
单链表
数据结构采用单向链表。
-
MyLinkedList中的成员有:- 哨兵结点dummy(这个不用过多介绍了,单链表题里很常见了)
- 当前链表的节点数size
-
当然我们要新建一个数据结构
Node,成员有:- 当前节点值Val
- 当前节点指向的下一个节点Next
那么定义数据结构的代码就如下:
1
2
3
4
5
6
7
8
9type MyLinkedList struct {
dummy *Node
size int
}
type Node struct {
Val int
Next *Node
} -
定义好了数据结构,构造函数
Constructor就比较好写了:1
2
3func Constructor() MyLinkedList {
return MyLinkedList{dummy: &Node{}, size: 0}
} -
get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。因为
MyLinkedList中有size这个成员变量,题目中也说了链表中的所有节点都是 0-index 的,所以就比较好写了。代码如下:1
2
3
4
5
6
7
8
9
10func (l *MyLinkedList) Get(index int) int {
if index < 0 || index >= l.size { // index不合法
return -1
}
cur := l.dummy
for i := 0; i <= index; i++ { // 因为cur是从哨兵节点开始的
cur = cur.Next
}
return cur.Val
} -
addAtHead(val):在链表的第一个元素之前添加一个值为val的节点。插入后,新节点将成为链表的第一个节点。这个没什么好说的,写好
addAtIndex(index,val)即可,然后在内部执行l.AddAtIndex(0, val)。代码如下:1
2
3func (l *MyLinkedList) AddAtHead(val int) {
l.AddAtIndex(0, val)
}(这里不
l.size++是因为在addAtIndex(index,val)中已经l.size++了) -
addAtTail(val):将值为val的节点追加到链表的最后一个元素。这个也没什么好说的,写好
addAtIndex(index,val)即可,然后在内部执行l.AddAtIndex(l.size, val)。代码如下:1
2
3func (l *MyLinkedList) AddAtTail(val int) {
l.AddAtIndex(l.size, val)
}(这里不
l.size++是因为在addAtIndex(index,val)中已经l.size++了) -
addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
处理一下边界条件,就可以开始链表的添加节点操作了。要在某一个节点前添加节点,我们要先找到该节点的前一个节点,即要在cur节点前添加一个节点,我们要找到cur节点的前一个节点pre(这个画一下图就可以理解了)。最后别忘了
l.size++。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16func (l *MyLinkedList) AddAtIndex(index int, val int) {
if index > l.size { // 如果index大于链表长度,则不会插入节点
return
}
if index < 0 { // 如果index小于0,则在头部插入节点
index = 0
}
// 接下来就是链表的添加操作了
pre := l.dummy
for i := 0; i < index; i++ {
pre = pre.Next
}
cur := pre.Next
pre.Next = &Node{Next: cur, Val: val}
l.size++ // 别忘了链表size+1
} -
deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。首先还是处理好边界条件(index不合法的情况),然后就是经典的单链表删除节点了。跟添加节点一样,要删除cur节点,我们要找到cur节点的前一个节点pre。最后别忘了
l.size--。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12func (l *MyLinkedList) DeleteAtIndex(index int) {
if index < 0 || index >= l.size { // index不合法
return
}
// 开始删除节点
pre := l.dummy
for i := 0; i < index; i++ {
pre = pre.Next
}
pre.Next = pre.Next.Next
l.size-- // 别忘了链表size-1
}
完整代码如下:
1 | type MyLinkedList struct { |
反转链表
代码随想录:
单链表
之前用Java写过,具体逻辑就不细说了。根据代码打下草稿就能懂。
代码如下:
1 | func reverseList(head *ListNode) *ListNode { |
两两交换链表中的节点
代码随想录:
双指针
因为这题要求:你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。所以就不能取巧去交换Val值。
这题我其实是有点取巧的:因为是单向链表且无循环,所以交换两个节点的处理我在这里是直接交换两个节点的Val值的:
cur.Val, next.Val = next.Val, cur.Val。这样处理一下其他的就很好写了,做一个循环,然后cur、next指针每次向后移动两位。代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
if head == nil {
return nil
}
cur, next := head, head.Next
for next != nil {
cur.Val, next.Val = next.Val, cur.Val // 交换两节点的val
cur = cur.Next.Next
if next.Next == nil { // 做一下判断,不然next = next.Next.Next会panic
break
}
next = next.Next.Next
}
return head
}
不取巧,真正的交换节点的代码,参考官方题解。
temp=dummy(哨兵节点dummy,这种处理不用再多说)- 每次循环中,
pre=temp.Next,next=temp.Next.Next - 要交换pre和next,那么就需要temp参与其中,3个指针来处理:
temp.Next=next、pre.Next=next.Next、next.Next=pre(这个逻辑打一下草稿就能懂) - 开始下一次循环,移动temp:
temp=pre(打下草稿就很清楚了) - 维持循环的条件:
temp.Next!=nil && temp.Next.Next!=nil(这个取一下节点奇偶数的特殊情况就能搞明白了,不需要加temp!=nil)
1 | func swapPairs(head *ListNode) *ListNode { |
删除链表的倒数第N个节点
代码随想录:
双指针
按照之前用Java写过的逻辑,求链表的的倒数第N个结点,使用双指针即可:
-
(因为涉及到删除,所以要让p1走到倒数第N个结点的前一个,这样更好删除(链表的添加和删除,一般都是走到目标链表的前一个,这个已经接触过很多了,不再多说))
-
初始p1,p2都为
dummyNode(dummyNode.Next = head),p2指针永远比p1指针快N个结点,然后同时移动p1和p2,这样当p2.Next==nil时,p1指向的即为链表的倒数第N个结点的前一个结点 -
找到了倒数第N个结点的前一个p1,要删除倒数第N个就很简单了(
p1.Next = p1.Next.Next)
思路很简单画一下图就能懂,代码如下:
1 | func removeNthFromEnd(head *ListNode, n int) *ListNode { |
链表相交
代码随想录:
哈希表
直接使用哈希表来判断是否有相交链表,思路简单暴力。
代码如下:
1 | func getIntersectionNode(headA, headB *ListNode) *ListNode { |
在Go中,空结构体
struct{}是不占任何内存的。因为空结构体不占据内存空间,因此被广泛作为各种场景下的占位符使用。一是节省资源。二是空结构体本身就具备很强的语义,即这里不需要任何值,仅作为占位符。(其中经典的用法就是用来实现集合Set。这里可以引申讲讲Go空结构体struct{})
双指针
使用双指针的方法,可以将空间复杂度降至 O(1)。
- 只有当链表headA 和 headB 都不为空时,两个链表才可能相交。因此首先判断链表 headA 和 headB 是否为空,如果其中至少有一个链表为空,则两个链表一定不相交,返回 null。
- 当链表headA 和 headB 都不为空时,创建两个指针pA 和pB,初始时分别指向两个链表的头节点 headA 和 headB,然后将两个指针依次遍历两个链表的每个节点。具体做法如下:
- 每步操作需要同时更新指针 pA 和 pB。
- 如果指针pA 不为空,则将指针 pA 移到下一个节点;如果指针 pB 不为空,则将指针 pB 移到下一个节点。
- 如果指针 pA 为空,则将指针pA 移到链表headB 的头节点;如果指针pB 为空,则将指针 pB 移到链表 headA 的头节点。
- 当指针pA 和pB 指向同一个节点时,返回它们指向的节点;若指针pA 和pB 都为空,返回null。

代码如下:
1 | func getIntersectionNode(headA, headB *ListNode) *ListNode { |
环形链表II
代码随想录:
哈希表
最简单易懂的方法了。
代码如下:
1 | func detectCycle(head *ListNode) *ListNode { |
- 执行用时:8 ms, 在所有 Go 提交中击败了29.52%的用户
- 内存消耗:5.8 MB, 在所有 Go 提交中击败了5.02%的用户
快慢指针
快慢指针,当slow指针和fast指针相遇后,再让ptr指针从头结点开始,和slow指针每次向后移动一个位置。最终,它们会在入环点相遇。
数学推论:
我们使用两个指针,fast 与 slow。它们起始都位于链表的头部。随后,slow指针每次向后移动一个位置,而 fast 指针向后移动两个位置。如果链表中存在环,则 fast 指针最终将再次与 slow 指针在环中相遇。
如下图所示,设链表中环外部分的长度为 a。 slow 指针进入环后,又走了 b 的距离与 fast 相遇。此时,fast 指针已经走完了环的 n 圈,因此它走过的总距离为 a+n(b+c)+b=a+(n+1)b+nc
根据题意,任意时刻,fast 指针走过的距离都为 slow 指针的 2 倍。因此,我们有
a+(n+1)b+nc=2(a+b)⟹a=c+(n−1)(b+c)
有了 a=c+(n−1)(b+c) 的等量关系,我们会发现:从相遇点到入环点的距离加上 n-1 圈的环长,恰好等于从链表头部到入环点的距离。
因此,当发现 slow 与 fast 相遇时,我们再额外使用一个指针 ptr。起始,它指向链表头部;随后,它和slow每次向后移动一个位置。最终,它们会在入环点相遇。
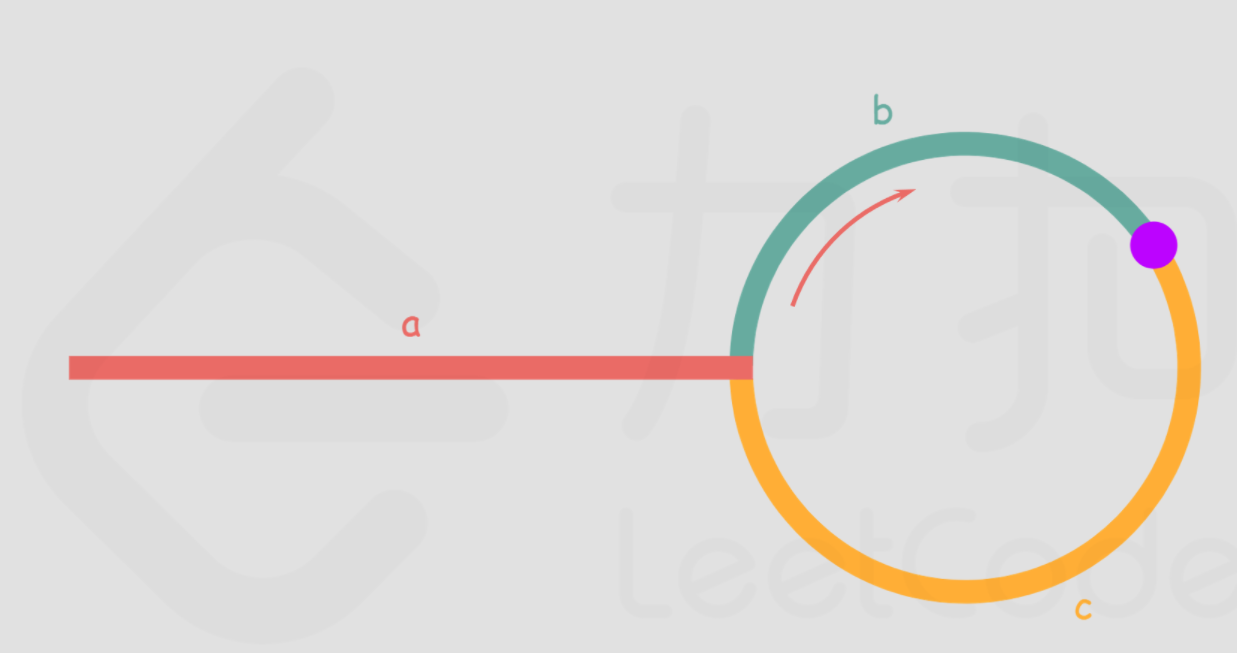
代码如下:
1 | func detectCycle(head *ListNode) *ListNode { |
- 执行用时:4 ms, 在所有 Go 提交中击败了94.83%的用户
- 内存消耗:3.5 MB, 在所有 Go 提交中击败了27.27%的用户




