数据库连接池原理介绍+常用连接池介绍
什么是连接池:数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。
视频讲解
数据库连接池概念:其实就是一个容器(集合),存放数据库连接的容器。当系统初始化后,容器被创建,容器中会申请一些连接对象,当用户访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
优点:
实现:
标准接口:DataSource (javax.sql包下),方法有:
获取连接:getConnection() 归还连接:connection.close() 如果连接对象Connection是从数据库连接池中获取的,那么调用connection.close()方法则不会关闭连接,而是归还连接
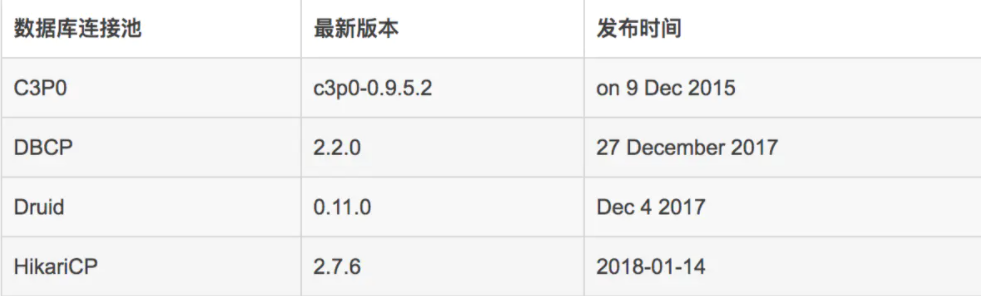
一般我们不用写实现类,有数据库厂商来实现。这里我们学习以下两种数据库连接池技术:
这里再说一下不同的数据库连接技术,在上述的推荐文章中也已经写到过了。
彻底死掉的C3P0
咸鱼翻身的DBCP
性能无敌的HikariCP
功能全面的Druid
Druid
强大的监控特性,通过Druid提供的监控功能,可以清楚知道连接池和SQL的工作情况。
方便扩展。Druid提供了Filter-Chain模式的扩展API,可以自己编写Filter拦截JDBC中的任何方法,可以在上面做任何事情,比如说性能监控、SQL审计、用户名密码加密、日志等等。
Druid集合了开源和商业数据库连接池的优秀特性,并结合阿里巴巴大规模苛刻生产环境的使用经验进行优化。
步骤:
导入jar包:c3p0-0.9.5.2.jar和mchange-commons-java-0.2.12.jar,再加上mchange-commons-java-0.2.12.jar 定义配置文件:
命名:c3p0.properties或c3p0-config.xml 路径:配置文件放在src目录下
创建核心对象:ComboPooledDataSource数据库连接池对象 获取连接:getConnection()
例子:
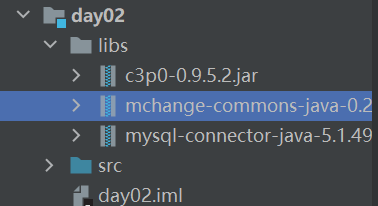
首先导包,和之前到msyql-connector包一样,我们将本地的c3p0-0.9.5.2.jar和mchange-commons-java-0.2.12.jar放到libs文件夹下,并Add as Library 。执行完成后效果为:
然后我们定义配置文件,在src路径下创建c3p0-config.xml,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <c3p0-config > <default-config > <property name ="driverClass" > com.mysql.jdbc.Driver</property > <property name ="jdbcUrl" > jdbc:mysql://localhost:3306/jdbc_study</property > <property name ="user" > root</property > <property name ="password" > 123456</property > <property name ="initialPoolSize" > 5</property > <property name ="maxPoolSize" > 10</property > <property name ="checkoutTimeout" > 3000</property > </default-config > <named-config name ="otherc3p0" > <property name ="driverClass" > com.mysql.jdbc.Driver</property > <property name ="jdbcUrl" > jdbc:mysql://localhost:3306/jdbc_study</property > <property name ="user" > root</property > <property name ="password" > 123456</property > <property name ="initialPoolSize" > 5</property > <property name ="maxPoolSize" > 8</property > <property name ="checkoutTimeout" > 1000</property > </named-config > </c3p0-config >
创建启动类C3P0Demo01.java代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package datasource.c3p0;import com.mchange.v2.c3p0.ComboPooledDataSource;import javax.sql.DataSource;import java.sql.Connection;import java.sql.SQLException;public class C3P0Demo01 public static void main (String[] args) throws SQLException DataSource dataSource = new ComboPooledDataSource(); DataSource dataSource1 = new ComboPooledDataSource("otherc3p0" ); Connection connection = dataSource.getConnection(); Connection connection1 = dataSource1.getConnection(); System.out.println(connection); System.out.println(connection1); } }
执行结果如下:
注意一下配置文件中我们除了默认(default)配置<default-config>,还有一个<named-config name="otherc3p0">。可以看一下详细讲解视频:
c3p0配置文件演示:视频讲解
Druid的使用 Druid数据库连接池技术,由阿里巴巴提供
步骤:
导入jar包 druid-1.2.5.jar 定义配置文件:.properties文件,可以任意取名,放在任意目录下 加载配置文件 new Properties() 获取数据库连接池对象:通过工厂来获取 DruidDataSourceFactory.createDataSource(properties) 获取连接 dataSource.getConnection()
基本使用例子:
导包后,创建druid.properties配置文件放在src目录下,代码如下:
1 2 3 4 5 6 7 driverClassName =com.mysql.jdbc.Driver url =jdbc:mysql://localhost:3306/jdbc_study username =root password =123456 initialSize =5 maxActive =10 maxWait =3000
然后创建启动类DruidDemo01.java,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package datasource.druid;import com.alibaba.druid.pool.DruidDataSource;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;import java.io.InputStream;import java.sql.Connection;import java.util.Properties;public class DruidDemo01 public static void main (String[] args) throws Exception Properties properties = new Properties(); InputStream inputStream = DruidDemo01.class.getClassLoader().getResourceAsStream("druid.properties"); properties.load(inputStream); DataSource dataSource = DruidDataSourceFactory.createDataSource(properties); Connection connection = dataSource.getConnection(); System.out.println(connection); } }
定义工具类
定义一个类 JDBCUtils 提供静态代码块加载配置文件,初始化连接池对象 提供方法
获取连接方法(通过数据库连接池获取连接) 释放资源 获取连接池方法
例子:我们在utils包下创建JDBCUtils.java工具类,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package utils;import com.alibaba.druid.pool.DruidDataSourceFactory;import datasource.druid.DruidDemo01;import javax.sql.DataSource;import java.io.IOException;import java.io.InputStream;import java.sql.Connection;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;import java.util.Properties;public class JDBCUtils private static DataSource dataSource; static { try { Properties properties = new Properties(); properties.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties")); DataSource dataSource = DruidDataSourceFactory.createDataSource(properties); } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } public static Connection getConnection () throws SQLException return dataSource.getConnection(); } public static void close (Statement statement, Connection connection, ResultSet resultSet) if (statement != null ) { try { statement.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } } if (connection != null ) { try { connection.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } } if (resultSet != null ) { try { resultSet.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } } } public static DataSource getDataSource () return dataSource; } }
注意:上述close方法并没有重载。如果要执行DML的close方法,将ResultSet设置为null即可。如:close(statement,connection,null)
要使用刚刚创建的工具类,我们创建主启动类Demo02代码,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package datasource.druid;import utils.JDBCUtils;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.SQLException;public class Demo02 public static void main (String[] args) Connection connection = null ; PreparedStatement preparedStatement = null ; try { connection = JDBCUtils.getConnection(); String sql = "insert into account values(3,'wangwu',2000)" ; preparedStatement = connection.prepareStatement(sql); int count = preparedStatement.executeUpdate(); System.out.println("一共执行了" +count+"条记录" ); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { JDBCUtils.close(preparedStatement,connection,null ); } } }
执行结果如下:
JDBC已经能够满足大部分用户最基本的对数据库的需求,但是在使用JDBC时,应用必须自己来管理数据库资源。spring对数据库操作需求提供了很好的支持,并在原始JDBC基础上,构建了一个抽象层,提供了许多使用JDBC的模板和驱动模块,为Spring应用操作关系数据库提供了更大的便利。
JdbcTemplate是core包的核心类。 它替我们完成了资源的创建以及释放工作,从而简化了我们对JDBC的使用。 它还可以帮助我们避免一些常见的错误,比如忘记关闭数据库连接。
JdbcTemplate系列(一)----使用详解
Spring JdbcTemplate框架(一)——基本原理
Spring 框架对JDBC的简单框架。提供了一个JDBCTemplate对象简化JDBC的开发。
关于spring框架的学习后续会继续深入,这里可以先了解一下
关于JDBCTemplate,这里有:Spring JDBC教程
步骤:
导入相关jar包
创建JDBCTemplate对象。参数可以是数据源DataSource
JdbcTemplate jdbcTemplate = new JdbcTemplate()
调用JDBCTemplate的方法来完成CRUD :
update():执行DML语句(增删改) queryForMap():查询结果,将结果封装为map集合,列名作为key,值作为value,将这条记录封装为一个map集合
注意:这个方法查询的结果集长度只能是1(即只能查询一条记录)
queryForList():查询结果,将结果封装为list集合
注意:将每一条记录封装为Map集合,再将Map集合装载到List集合中
query() :查询结果,将结果封装为JavaBean 对象。并将这个结果放到List中 (即返回一个List )
query的参数:RowMapper
一般我们使用BeanPropertyRowMapper实现类,可以完成数据到JavaBean的自动封装:new BeanPropertyRowMapper<类型>(类型.class)
queryForObject() :查询结果,将结果封装为对象。返回一个对象
一般我们使用BeanPropertyRowMapper实现类,可以完成数据到JavaBean的自动封装:new BeanPropertyRowMapper<类型>(类型.class) queryForObject()一般用于聚合函数 的查询
(关于JavaSE中的有道云笔记:Map ,List ,ArrayList )
JDBCTemplate入门程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package jdbcTemplate;import org.springframework.jdbc.core.JdbcTemplate;import utils.JDBCUtils;public class Demo01 public static void main (String[] args) JdbcTemplate jdbcTemplate = new JdbcTemplate(JDBCUtils.getDataSource()); String sql = "update account set balance = 5000 where id = ?" ; int count = jdbcTemplate.update(sql, 3 ); System.out.println("一共执行了" +count+"条记录" ); } }
练习的emp表数据如下:
需求(包含DML和DQL):
修改1号数据的salary为10000
添加一条记录
删除刚刚添加的记录
查询id为1001的记录,将其封装为Map结合
查询所有记录,将其封装为List
查询所有记录,将其封装为Emp对象的List集合 查询记录总数
首先还是要在domain包下先创建Emp类,代码同之前的笔记
这里为了方便,我们使用Junit单元测试 。之前的笔记也有写过。这样可以让方法独立执行而不依赖于主方法 。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 package jdbcTemplate;import domain.Emp;import org.junit.Test;import org.springframework.jdbc.core.BeanPropertyRowMapper;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.jdbc.core.RowMapper;import utils.JDBCUtils;import java.math.BigDecimal;import java.sql.Date;import java.sql.ResultSet;import java.sql.SQLException;import java.util.List;import java.util.Map;public class Demo02 JdbcTemplate jdbcTemplate = new JdbcTemplate(JDBCUtils.getDataSource()); @Test public void test1 () String sql = "update emp set salary = 10000 where id = ?" ; int count = jdbcTemplate.update(sql,1001 ); System.out.println("一共执行了" + count + "条记录" ); } @Test public void test2 () String sql = "insert into emp values (?,?,4,1007,20011011,13000.00,4000,20)" ; int count = jdbcTemplate.update(sql,1015 ,"赵子龙" ); System.out.println("一共执行了" + count + "条记录" ); } @Test public void test3 () String sql = "delete from emp where id = ?" ; int count = jdbcTemplate.update(sql,1015 ); System.out.println("一共执行了" + count + "条记录" ); } @Test public void test4 () String sql = "select * from emp where id = ?" ; Map<String, Object> map = jdbcTemplate.queryForMap(sql, 1001 ); System.out.println(map); } @Test public void tes5 () String sql = "select * from emp" ; List<Map<String, Object>> mapList = jdbcTemplate.queryForList(sql); for (Map<String, Object> map : mapList) { System.out.println(map); } } @Test public void tes6_1 () String sql = "select * from emp" ; List<Emp> emps = jdbcTemplate.query(sql, new RowMapper<Emp>() { @Override public Emp mapRow (ResultSet resultSet, int i) throws SQLException int id = resultSet.getInt("id" ); String ename = resultSet.getString("ename" ); int job_id = resultSet.getInt("job_id" ); int mgr = resultSet.getInt("mgr" ); Date joindate = resultSet.getDate("joindate" ); BigDecimal salary = resultSet.getBigDecimal("salary" ); BigDecimal bonus = resultSet.getBigDecimal("bonus" ); int dept_id = resultSet.getInt("dept_id" ); Emp emp = new Emp(); emp.setId(id); emp.setEname(ename); emp.setJob_id(job_id); emp.setMgr(mgr); emp.setJoindate(joindate); emp.setSalary(salary); emp.setBonus(bonus); emp.setDept_id(dept_id); return emp; } }); for (Emp emp : emps) { System.out.println(emp); } } @Test public void tes6_2 () String sql = "select * from emp" ; List<Emp> emps = jdbcTemplate.query(sql, new BeanPropertyRowMapper<Emp>(Emp.class )) ; for (Emp emp : emps) { System.out.println(emp); } } @Test public void tes7 () String sql = "select count(id) from emp" ; Long count = jdbcTemplate.queryForObject(sql, Long.class ) ; System.out.println("记录总数为:" +count); } }
其中解决插入中文数据乱码的解决方式为: jdbc连接数据库插入中文数据乱码问题
解决test_2中,null不能转换成int的错误:将Eem中的Integer改成包装类
(JAVA基本类型和包装类 ,之前的包装类笔记 )