MySQL(一)
推荐一下读物:《MySQL必知必会》(本地有可查看)
数据库
数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息等等。除了文本类型的数据,图像、音乐、声音都是数据。
数据库,DataBase,简称DB。用来存储和管理数据的仓库
数据库特点:
- 持久化存储数据
- 方便存储和管理数据
- 使用统一的方式操作数据库(SQL)
常见数据库软件:
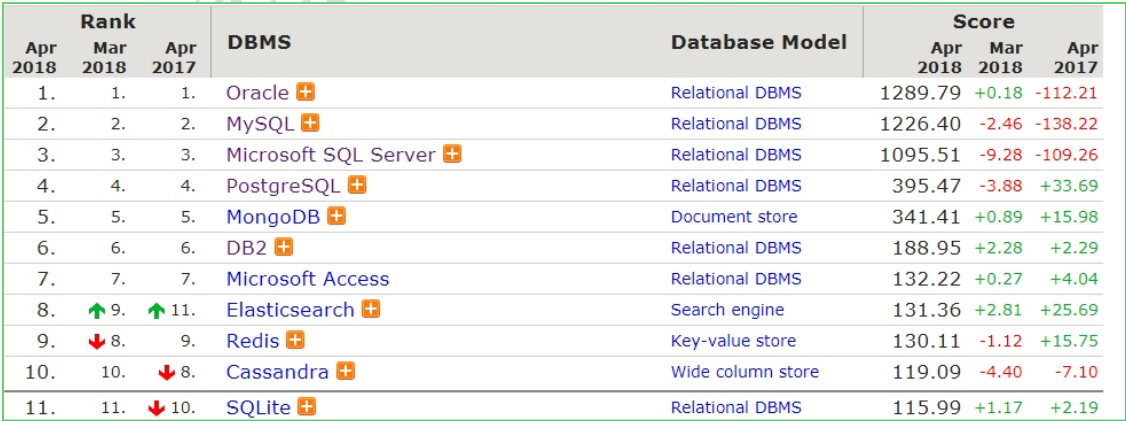
- MySQL:开源免费的数据库,小型的数据库,已经被 Oracle 收购了。MySQL6.x 版本也开始收费。后来 Sun公司收购了 MySQL,而 Sun 公司又被 Oracle 收购
- Oracle:收费的大型数据库,Oracle 公司的产品
- DB2 :IBM 公司的数据库产品,收费的。常应用在银行系统中。
- SQL Server:MicroSoft 公司收费的中型的数据库。C#、.net 等语言常使用。
- SQLite: 嵌入式的小型数据库,应用在手机端,如:Android。
在Web应用中,使用最多的是MySQL数据库,因为其开源,免费,且功能足够强大,足以应付web应用开发(最高支持千万级别的并发访问)
关系型数据库和非关系型数据库
关系型数据库:Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL等
非关系型数据库:NoSql、Cloudant、MongoDB、redis、HBase等
开始MySql
MySql的安装和卸载网上已经有很多教程了。(如果是Windows本地安装,最好选择zip安装,这样卸载起来也方便些)
Mysql服务的启动和关闭网上也有很多教程。
MySQL的登录:
mysql -uroot -pmysql -hip -uroot -p(ip为指定连接的MySQL的ip地址)mysql --host=ip 地址 --user=用户名 --password=密码
MySQL退出:
exitquit
SQL
SQL,Structured Query Language,结构化查询语言
其实就是定义了操作所有关系型数据库的规则(每一种数据库操作方式存在不一样的地方,理解为“方言”)
这里推荐一篇博客:文章链接
SQL通用语法
- SQL语句可以单行或者多行书写,以分号
;结尾 - 可以使用空格和缩进来增强语句的可读性
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
- 注释语法
- 单行注释:
-- 注释内容或#注释内容(#为msyql特有) - 多行注释:
/*注释内容*/
- 单行注释:
SQL分类
-
DDL,Data Definition Language,数据定义语言。用来定义数据库对象:数据库,表,列等。关键字:create, drop,alter 等
-
DML,Data Manipulation Language,数据操作语言。用来对数据库中表的数据进行增删改。关键字:insert, delete, update 等
-
DQL,Data Query Language,数据查询语言。用来查询数据库中表的记录(数据)。关键字:select, where 等
-
DCL,Data Control Language,数据控制语言(了解)。用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT, REVOKE 等
DDL:操作数据库、表
关于DDL的所有操作,以后我们都可以在Navicat上的图形化界面进行操作。
操作数据库
CRUD,(Create(创建)、Retrieve(查询)、Update(修改)、Delete(删除)),增删改查。
Create(创建)
1 | create database 数据库名称; -- 创建数据库 |
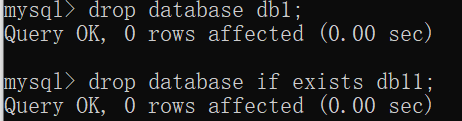
例子:我们创建数据库db11,先判断是否存在,并指定字符集为gbk
1 | create database if not exists db11 character set gbk; |

Retrieve(查询)
1 | show databases; -- 查询所有数据库名称 |
1 | show create database 数据库名称; -- 查看某个数据库的字符集 |

Update(修改)
1 | alter database 数据库名称 character set 字符集名称; -- 修改数据库字符集 |

Delete(删除)
1 | drop database 数据库名称; -- 删除指定数据库 |
使用数据库
1 | use 数据库名称 -- 使用指定数据库 |

操作表
Create(创建)
1 | create table 表名( |
注意:最后一列,不需要加逗号,
数据类型:(可查看本地有道云笔记,网上也有很多文章,这里推荐一篇:MySQL数据类型)
-
int 整数类型 (
age int) -
double 小数类型 (
score double(5,2)) -
date 日期,只包含年月日,yyyy-MM-dd
-
datatime 日期,包含年月日时分秒,yyyy-MM-dd HH:mm:ss
-
timestamp 时间戳,包含年月日时分秒,yyyy-MM-dd HH:mm:ss(如果将来不给这个字段赋值,或者赋值为null,则默认使用当前的系统时间,来自动赋值)
-
varchar 字符串(
name varchar(20),表示name字段最多20个字符(注意:zhangsan是8个字符,张三是2个字符)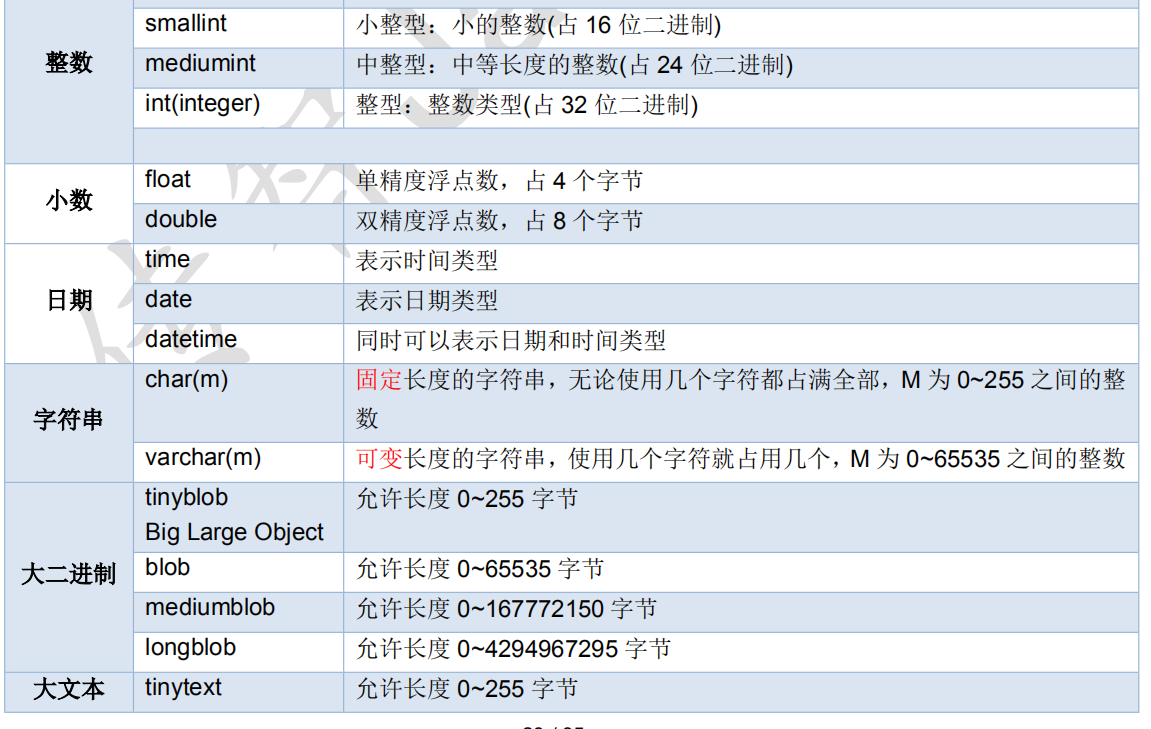
例子:我们创建一个student2表,字段有id,name,age,score,birthday,insert_time。SQL语句如下:
1 | create table student2( |

复制表
1 | create table 表名 like 被复制的表名; |

Retrieve(查询)
1 | show tables; -- 查询某个数据库中所有的表名称 |
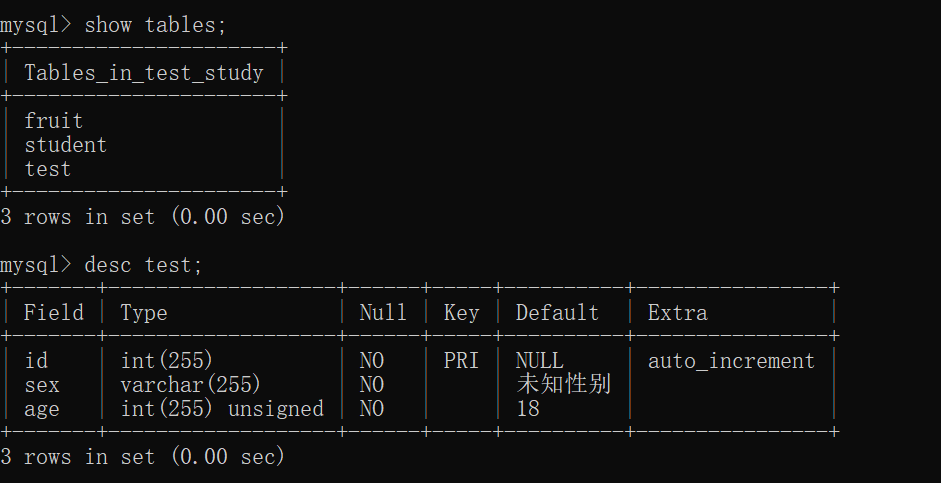
Update(修改)
1 | alter table 表名 rename to 新的表名; -- 修改表名 |


Delete(删除)
1 | drop table 表名; -- 删除指定表名 |

DML:增删改表中的数据
以后在项目中用的最多的还是DML语句,对表中的数据进行操作。
增加数据
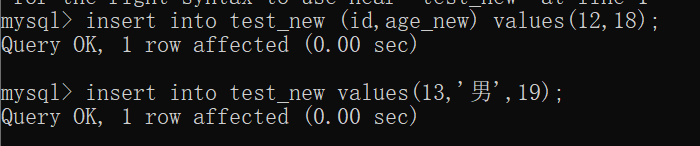
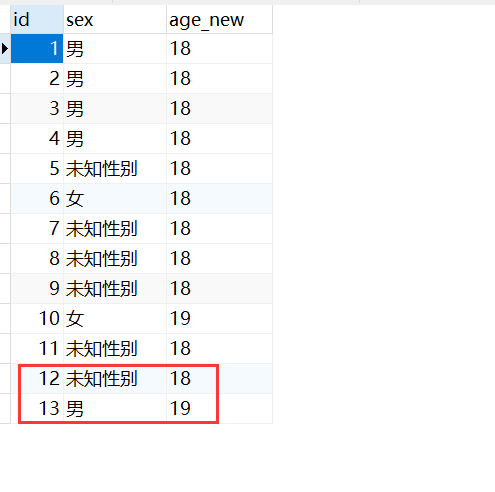
1 | insert into 表名 (列名1,列名2,...列名n) values(值1,值2,值n); -- 添加数据 |
注意:
- 列名和值要一一对应
- 如果表名后不定义列名,则默认给所有列添加数据(
insert into 表名 values(值1,值2,...值n);) - 除了数字类型,其他类型需要使用引号引起来(单引号双引号都可)
删除数据
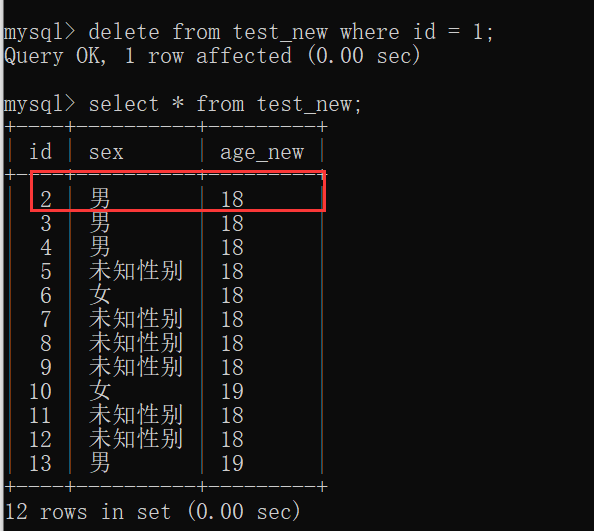
1 | delete from 表名 where 条件; -- where 条件 ,可以不写 |
注意:
- 如果不加条件,则删除表中所有记录
- 如果要删除表中所有记录:
delete from 表名;,不推荐使用。因为这样有多少条记录就要执行多少次删除操作,效率不高truncate table 表名;,推荐使用。先删除表,然后再创建一张表结构一样的表(数据为空)
修改数据
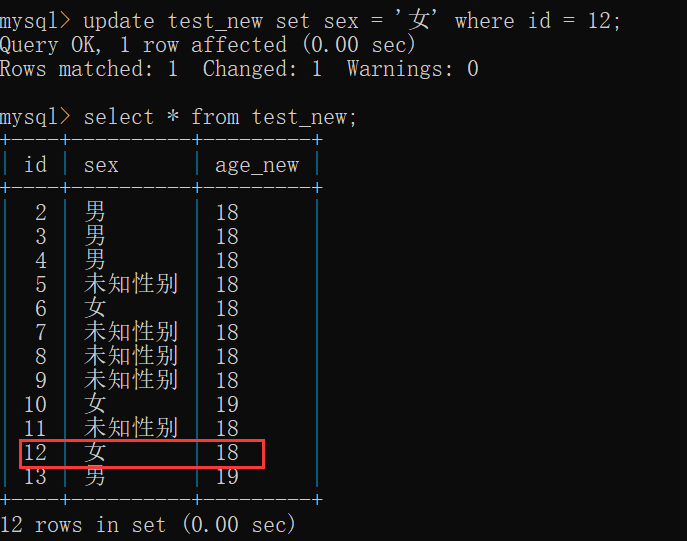
1 | update 表名 set 列名1=值1,列名2=值2,...列名n=值n where 条件; -- where 条件 ,可以不写 |
注意:
- 如果不加任何条件,则表中所有记录全部被修改
DQL:查询表中的数据
-
基础查询
-
条件查询
-
排序查询
-
聚合函数
-
分组查询
-
分页查询
1 | select |
基础查询
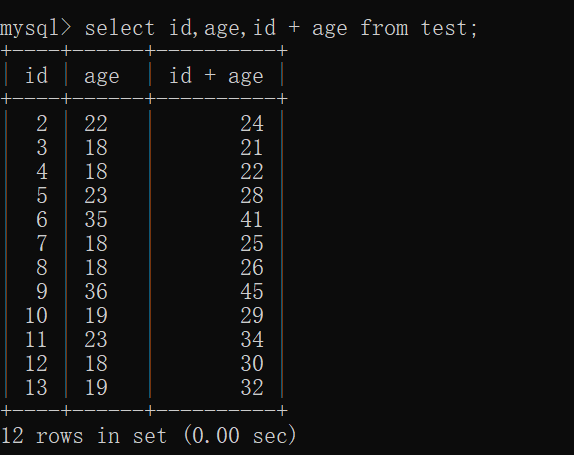
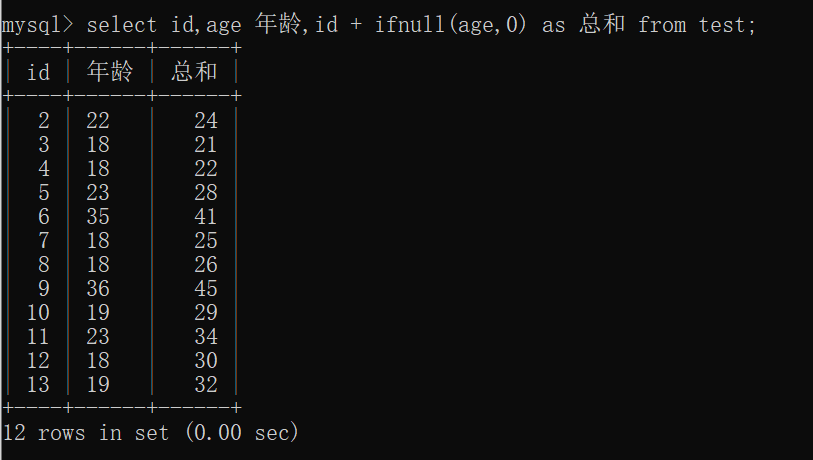
1 | select 字段名1,字段名2... ,字段名n from 表名; -- 多个字段查询 |

条件查询
where子句后面跟条件
运算符:
-
>,<,>=,<=,=,<>(其中<>在SQL中表示不等于,在mysql中也可以使用!=,没有==) -
between...and在一个范围之内(如between 100 and 200表示条件在100到200之间) -
in(集合) 集合表示多个数,使用逗号,分隔 -
like’%’ 模糊查询(如like’马%’ )
- 占位符:
_:单个任意字符%:多个任意字符
- 占位符:
-
and或&&与(SQL中建议使用and,&&并不通用) -
or或||或 -
not或!非
例子:
1 | select * from test; -- 查询test表中所有数据 |
模糊查询
like’%’ 模糊查询(如like’马%’ )
- 占位符:
_:单个任意字符%:多个任意字符
例子:
1 | select * from test where name like '张%'; -- 查询所有姓张的数据(即张xx) |
排序查询
1 | order by 子句; -- 详细展开就是: |
注意:如果有多个排序条件,只有当前边的条件值一样时,才会判断第二条件
例子:
1 | select * from test order by age desc , id; -- 按照age降序排,若age相同,则按照id升序排(因为默认升序所以没有写asc) |

聚合函数
聚合函数:将一列数据作为一个整体,进行纵向的计算。
mysql中的聚合函数如下:
- count:计算个数
- max:求出最大值
- min:求出最小值
- sum:计算和
- avg:计算平均值
注意:聚合函数的计算会排除null值(null值不参与聚合函数的计算)
例子:
1 | select count(name) from test; -- 查询表中的数据个数(因为null值不参与聚合函数的计算,所以结果为12) |

分组查询
1 | group by 分组字段; |
注意:
- 分组之后查询的字段只能是两种:分组字段和聚合函数(理解为分组之后看成整体,个体字段没有意义)
where和having的区别:- where在分组之前进行限定,若不满足条件则不参与分组;having在分组之后进行限定,若不满足条件则不会被查询出来(where是分组前的条件,having是分组后的条件)
- where后不可以跟聚合函数,having可以进行聚合函数的判断
例子:
1 | select sex,avg(age) from test group by sex; -- 根据性别分组,求出各组的年龄平均值 |

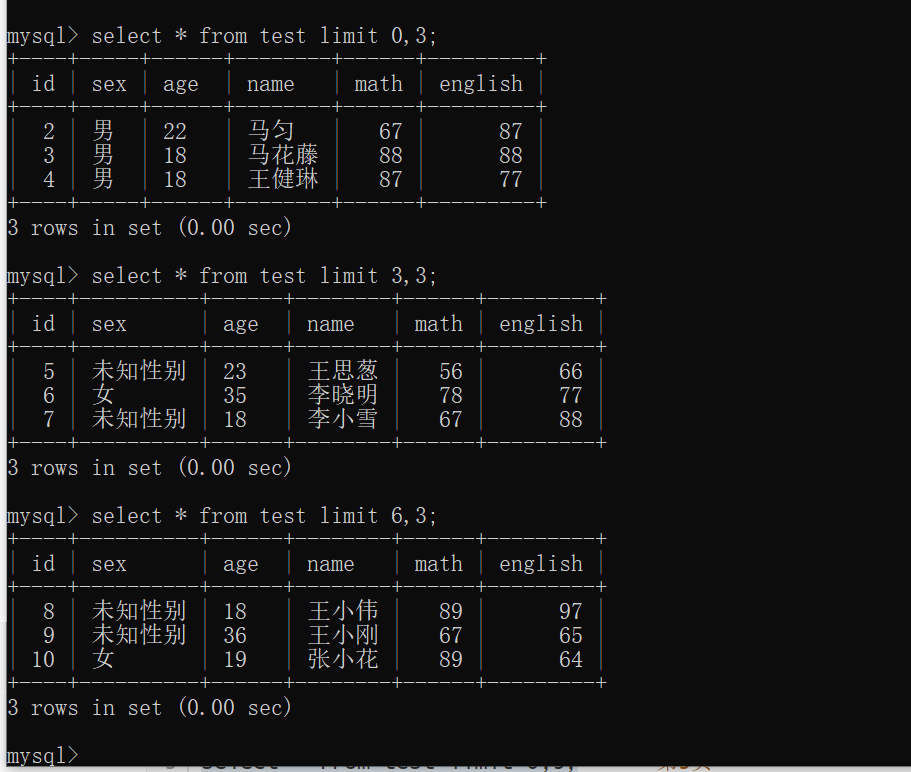
分页查询
1 | limit 开始的索引,每页查询的条数 |
公式:开始的索引=(当前的页码-1) * 每页显示的条数
注意:limit是MySQL里特有的(MySQL里的方言)
例子:
1 | select * from test limit 0,3; -- 第1页 |